使用CPU
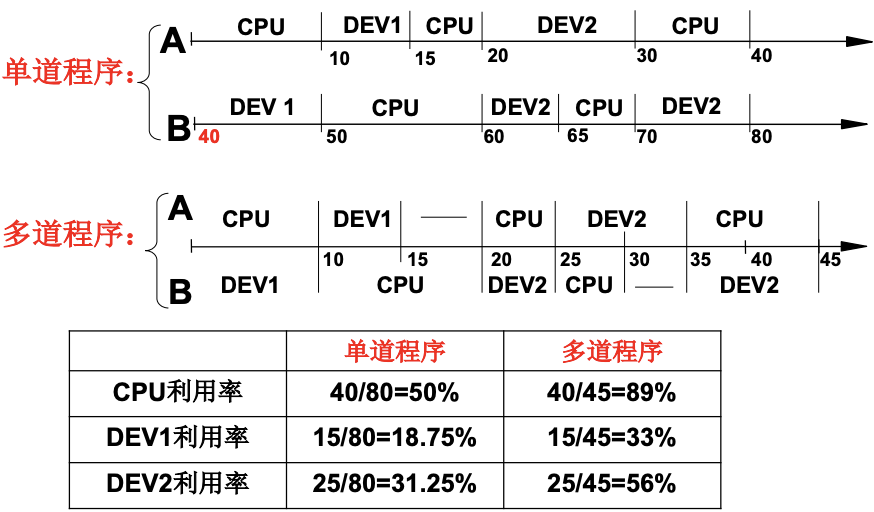
如果CPU只是简单地取址执行, 很多时间就会浪费在IO上, 因为IO通常是机械动作, 而CPU是电路工作, 所以这样就会降低CPU的使用率. 所以我们希望多道程序交替地执行, 来提升CPU地利用率. 下图的数字就是时间单位, 可以看出多道程序比单道程序的CPU利用率/设备的利用率都有了显著的上升. 这就是多道程序同时放在内存中同时出发, 交替执行. 而这个同时出发就是并发.
因为程序切出去再切回来之后, 我们想要记录切出去之前的程序的样子(寄存器保存的值, PC指向哪个地址), 每个程序存放这个信息的结构就是PCB(Process Control Block). 所以我们可以看出, 放在磁盘上的程序和运行中的程序是不同的, 这种正在进行中的程序就是进程, 进程要记录ax, bx等寄存器的值等等东西, 而程序是不用的. 这里可以联想JVM的运行时数据区.
多进程
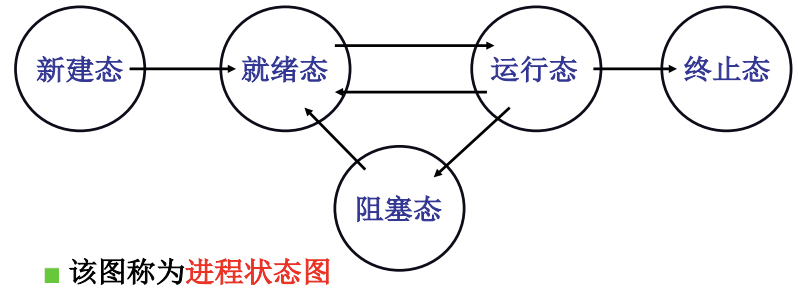
操作系统把多个进程记录好, 按照合理的次序推进(分配资源, 进行调度), 就是多进程的图像. 那么如何组织呢? 其实就是用PCB记录进程并把他们放在队列中, 并用状态来推进进程, 我们可以看到主要就是PCB+状态+队列这三个元素. 进程状态图如下:
笼统的多进程交替的过程如下:
启动磁盘读写;
pCur.state = ‘W’; // 进程变成阻塞态
将pCur放到DiskWaitQueue; // 进程放在阻塞磁盘等待队列
schedule(); // 切换
schedule() {
pNew = getNext(ReadyQueue); // 在就绪队列中找到下一个进程, 这个getNext就是调度(FIFO, Priority)
switch_to(pCur,pNew); // 从当前进程的PCB切换到下一个进程的PCB
}
switch_to(pCur,pNew) { // 这段代码实际上只能用汇编, 因为操作系统必须精细地控制各个寄存器
// 把CPU的信息保存在结构体中
pCur.ax = CPU.ax;
pCur.bx = CPU.bx;
...
pCur.cs = CPU.cs;
pCur.retpc = CPU.pc;
// 把当前结构体的信息赋给CPU
CPU.ax = pNew.ax;
CPU.bx = pNew.bx;
...
CPU.cs = pNew.cs;
CPU.retpc = pNew.pc;
}
因为多进程同时存在于内存中, 就会出现下图中地址冲突的现象. 解决办法是限制对地址100的读写, 这是后面会讲到的内存管理. 一般通过映射表将这个100映射到不同的物理内存地址.

多个进程合作也很重要, 比如典型的生产者-消费者问题, 两个进程会出现冲突, 进程切换必须合理, 否则如果两个进程共享数据, 他们按照混乱的顺序读写这个数据, 就很有可能出错. 比如下图counter本来是5, 最后一行counter却变成了4. 所以要对这个counter上锁.

可以概括为4件事, 后三点会一一介绍:
- 进程状态(当前阻塞并放在DiskWaitQueue)
- 进(线)程切换
- 分离进程
- 进程合作
用户级线程
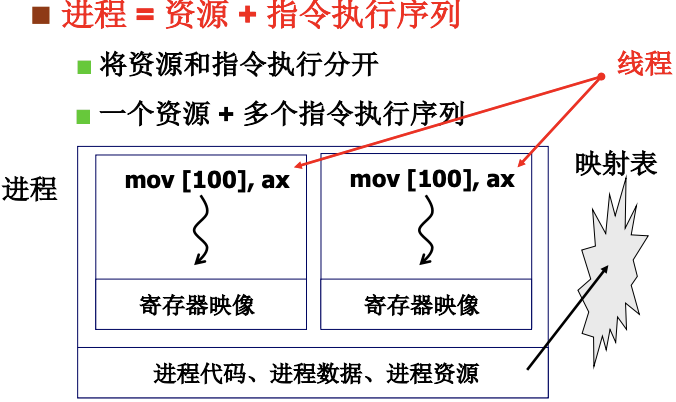
进程 = 资源(映射表) + 指令执行序列(线程thread). 线程切换保留了并发的优点, 又避免了进程切换代价. 而线程切换实际上就是就是映射表不变而PC指针变. 这一讲只涉及指令的切换, 也就是线程切换, 后面讲内存管理的时候就会讲资源的切换, 也就是进程的切换.
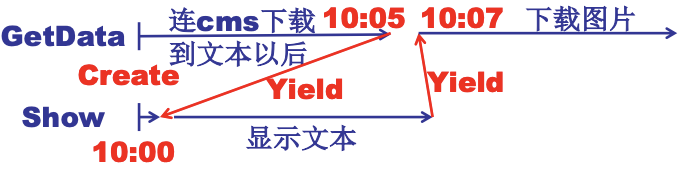
为什么多线程有价值呢? 多线程实际上就是多个执行序列和一个地址空间的场景. 当网页浏览器加载的时候, 接受数据都在同一个地址上, 我们希望用一个线程用来从服务器接收数据, 一个线程用来显示文本, 一个线程用来处理图片等, 去使网页逐渐加载出来, 这时候用多线程效果就会很好, 因为线程共享接收数据这个资源. 如果是多进程, 反而每次切换都要去复制这个接收数据的地址, 效率就不高了.
实现的过程如下:
void WebExplorer() {
char URL[] = “http://cms.hit.edu.cn”;
char buffer[1000]; // 申请共享缓冲区接收数据
pthread_create(..., GetData, URL, buffer); // 接收数据线程
pthread_create(..., Show, buffer); // 展示线程
}
void GetData(char *URL, char *p){...}; // 启动线程
void Show(char *p){...}; // 启动线程
多个Create的目的就是同时出发, Yield就是切换(使线程交替进行).
首先看两个执行序列与一个栈的情况. 下图中的数字代表地址, 当函数切换时, 就会把这个返回地址压栈. 当(3)执行完之后, 弹出的返回地址是错误的404, 而正确的应该是204.
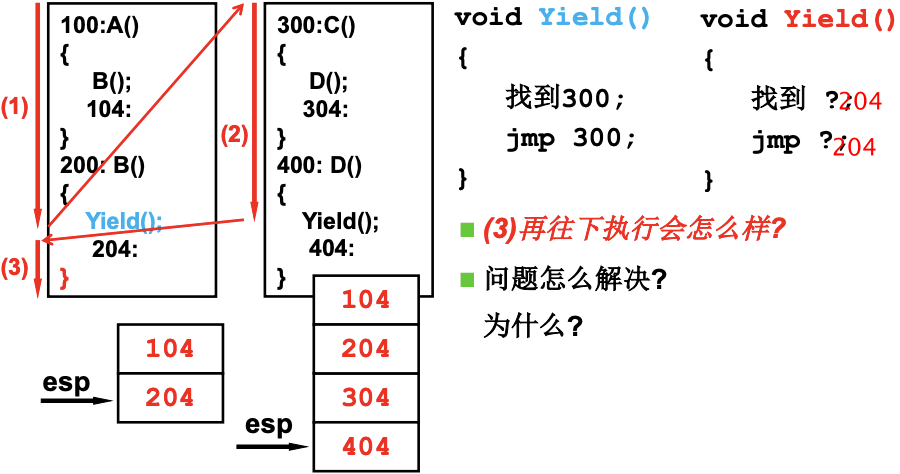
所以需要两个栈, 引入了TCP(Thread Control Block), 用来存放栈的指针, 线程切换时, 就会跳到另一个线程需要继续执行的位置. 图片中的jmp 204;是多余的, 因为切换后在回到这个线程, 自然就能出栈.
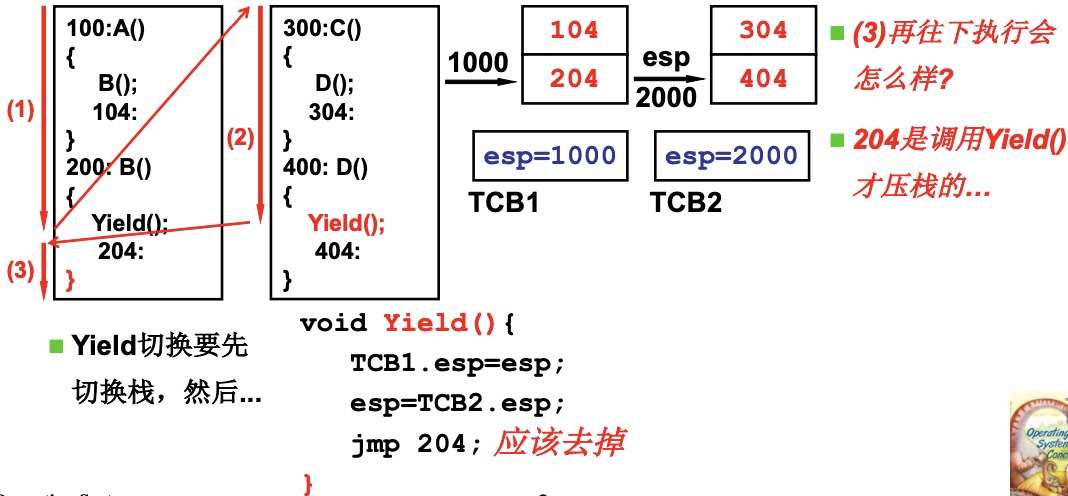
如何Create? 把两个TCB/两个栈/栈中切换的PC初始化出来.
void ThreadCreate(A) {
TCB *tcb=malloc(); // 创建TCB
*stack=malloc(); // 创建栈
*stack = A; //100, 开始地址
tcb.esp=stack; // 关联栈和TCB
}
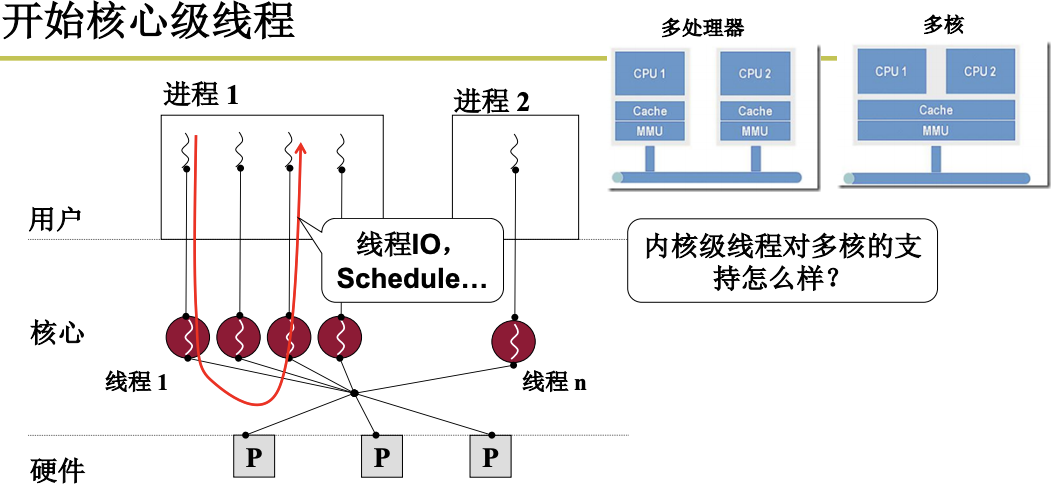
一个进程下的某个用户级线程在系统调用时如果被阻塞, 那么CPU就是执行另外一个进程, 而该进程下的线程就都无法进行了, 所以不仅要有用户级线程, 也要有核心级线程.
内核级线程
核心级线程才能充分利用多核, 下图的MMU是内存的映射, 只有多核才能实现多个执行序列用一套映射, 操作系统才能为每一个线程分配核心来执行, 实现并行. 多进程用的映射不同, 无法利用多核, 因为因为多核共用MMU. 用户级线程没有到内核, 从操作系统无法为其分配硬件, 也无法利用多核.
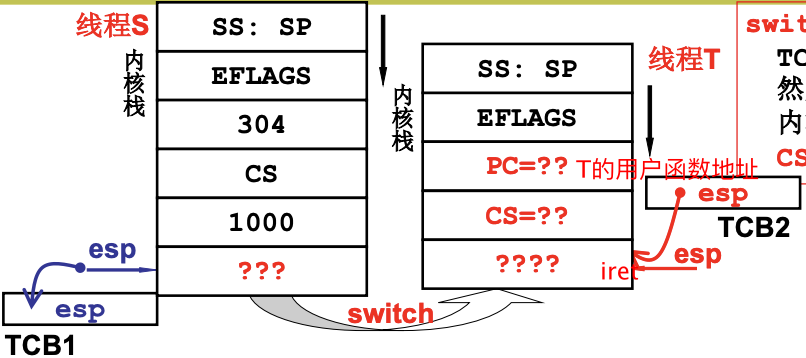
用户级线程只有一个栈, 而核心级线程有一套内核栈. 下图的304是IP. 我们叫这个线程S. SS:SP将内核栈和用户栈关联.
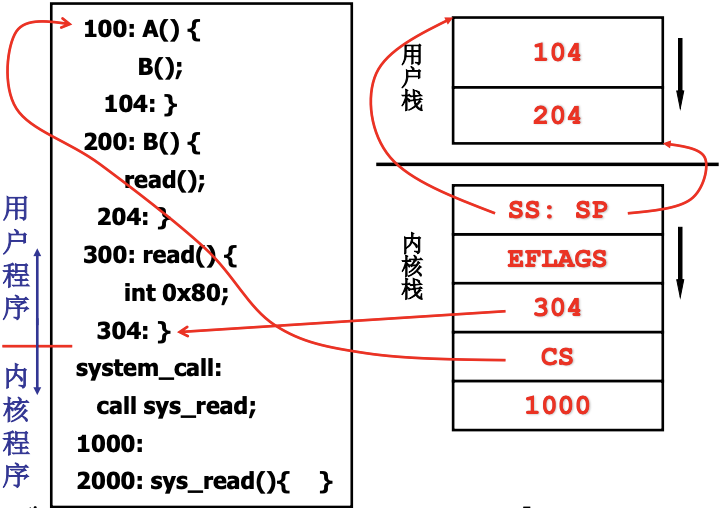
当中断发生, 就可以进入内核, 找到TCB. 如果发生了阻塞, 这个时候S走到了sys_read的某个地方, 会从线程S切换到线程T, 执行switch_to(cur, next), 完成线程切换, 这里的cur和next指当前TCB和线程T的TCB. 当T执行到了iret, 完成中断返回, 从T的内核栈切换到T的用户栈(PC和CS出栈), 指令执行地址也跳回, SS:SP出栈, 则T的用户栈也知道了, 开始真正得执行T的用户程序.
简单地说就是让switch_to通过TCB找到内核栈指针, 通过ret切到某个内核程序, 最后再用CS:PC切到用户程序.
内核级线程实现(todo)
暂跳过
CPU调度策略
之前讲了怎么切换进程, 那么我们怎么知道切换到哪一个进程了, 这种时候就需要CPU调度. 需要在吞吐量(完成的任务量, 内耗时间会影响此)和响应时间(从操作到完成反应)之间做一个trade off. 一般来说, 响应时间小->切换次数多->系统内耗大->吞吐量小.
有的时候我们并不在意进程什么时候结束, 比如打开了一个word过后我们不在意什么时候关掉它, 而是更在意打字反映在屏幕上的速度快. 所以说前台任务(IO相关)更加关注响应时间, 后台任务关注周转时间(CPU相关).
FCFS -> SJF
先到先服务(First Come, First Served) 如下, 周转时间指一个进程从开始到结束的时间, 因为到达时间很短, 所以忽略掉. 可以看到, 如果P3在P2之前, 那么平均周转时间就会缩小. 这就是短作业优先, 使周转时间少的进程在前.
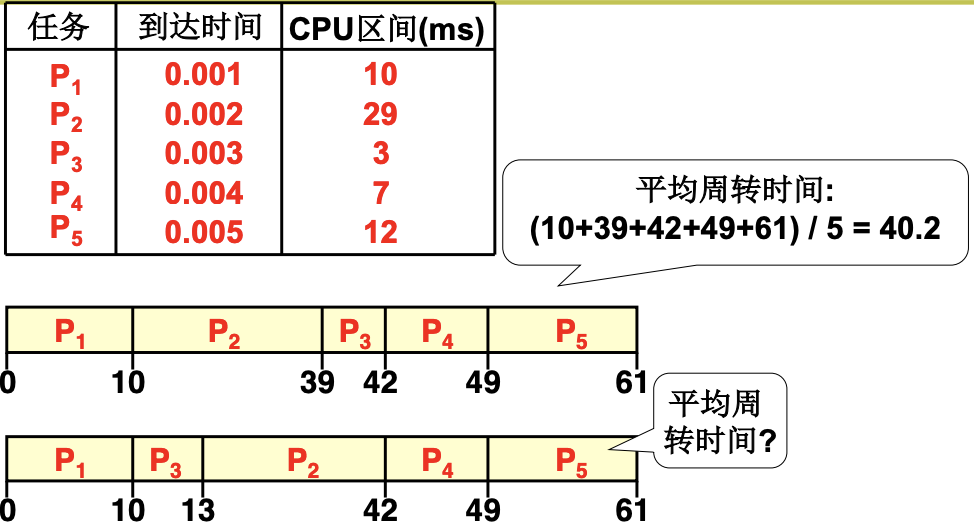
RR
时间片轮转调度算法(Round robin) 把进程分成时间片, 给每个进程分配时间片, 在该时间片内让进程运行. 当时间片大, 响应时间就会变长, 时间片小, 吞吐量就会变小.
优先级调度
可以让前台任务RR, 后台SJF, 总体上按照优先级调度. 优先级必须是动态的, 否则高优先级进程可能使得低优先级进程无法运行, 发生饥饿.
Linux 0.11的调度函数schedule()
counter既是涵盖了优先级, 也表示了时间片.
void Schedule(void) { //在kernel/sched.c中
while(1) {
c = -1; next = 0; i = NR_TASKS;
p = &task[NR_TASKS]; // p指向数组末尾
while(--i) {
if (*p->state == TASK_RUNNING && (*p)->counter>c) // 就绪并且counter大于c
c=(*p)->counter, next=i; // c是当前最大的counter
}
if (c) break; //找到了最大的counter, 也就是优先级最高的进程
// 就绪态时间片都是0, 非就绪态的进程阻塞, 就会执行下面的代码. 体现counter的优先级属性
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
// 右移一位相当于减半, 那么就绪态进程的counter就是初值, 阻塞的进程是当前counter减半加上初始优先级,
// 所以之前因为进行io而阻塞进程counter就会更高, 会被优先执行
(*p)->counter = ((*p)->counter>>1) + (*p)->priority;
}
switch_to(next); // 执行counter最大的进程
}
counter的时间片属性如下, 保证了时间片轮转, 近似的也是SJF, 因为周转时间短的进程一般会先结束.
void do_timer(...) { //在kernel/sched.c中
if((--current->counter>0) return; // counter随着时间自减
current->counter=0;
schedule();
}
_timer_interrupt: //在kernel/system_call.s中
...
call _do_timer
void sched_init(void) {
...
set_intr_gate(0x20, &timer_interrupt);
}
counter保证了响应时间的界, $c(t) = c(t-1)/2 + p$并且$c(0) = p$, 这是收敛的几何级数, 那么$c(\infty) \le 2P$, 也就是最长的时间片就只2P了. counter同时照顾前台进程(响应时间), 后台进程(周转时间).
进程同步与信号量
多进程之间需要合作, 如生产者-消费者任务, 那么进程之间就需要合理/有序地进行, 并在合适的时间等待. 下图中, 当缓冲区满了, 生产者就需要停止生产, 调用sleep(), 当counter为0了, 消费者就需要停止消费. 通过wakeup()就可以互相唤醒. 可是单纯的用这样的信号会有问题. 举例来说, 当两个进程P1, P2都要生产, 可是缓冲区已满, 此时两个进程都会sleep, 当消费者进程开始运行, 运行if(counter == BUFFER_SIZE-1), 那么P1被唤醒. 这时候这个if就永远不会执行了, 那么P2就只能一直保持sleep状态. 所以需要信号量, 去记录一些信息量(几个进程在等待),并根据这个信息决定睡眠还是唤醒(信号).
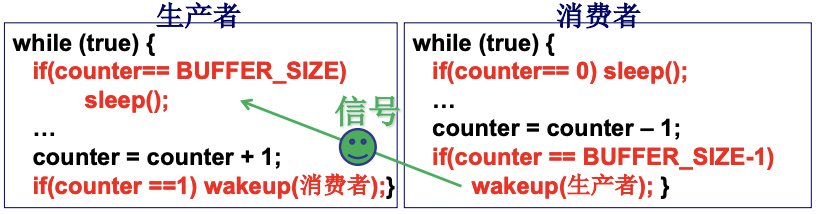
信号量通过一个整形变量来表示多少个进程在运行/在等待. 负数为等待. P的名称来源于荷兰语的proberen(test), V的名称也来源于荷兰语verhogen(increment). P和V都是系统调用.
struct semaphore
{
int value; //记录资源个数
PCB *queue; //记录等待在该信号量上的进程, 阻塞队列(在队列中等待), 记录在PCB中
}
P(semaphore s); //消费资源
V(semaphore s); //产生(释放)资源
P(semaphore s)
{
s.value--;
if (s.value < 0) { // 自减之前没有资源
sleep(s.queue);
}
}
V(semaphore s)
{
s.value++;
if (s.value <= 0) { // 只要是自加之前小于零, 就需要唤醒
wakeup(s.queue);
}
}
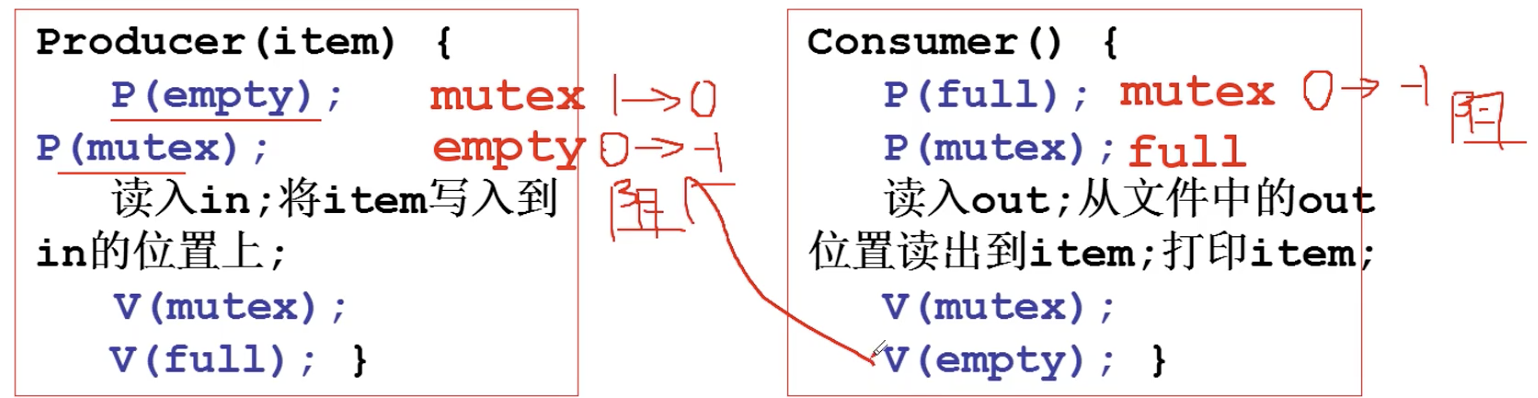
对生产者-消费者问题:
int fd = open(“buffer.txt”); // 用文件定义共享缓冲区
write(fd, 0, sizeof(int)); //写in
write(fd, 0, sizeof(int)); //写out
semaphore full = 0; // 已生产个数
semaphore empty = BUFFER_SIZE; // 空闲缓冲区大小(个数)
semaphore mutex = 1; //互斥信号量, 一次只能有一个进程访问资源
Producer(item) {
P(empty); // 缓冲区满没有, 满就停, 缓冲区满就是空闲缓冲区为0
P(mutex); // 是否有其他进程
读入in; 将item写入到in的位置上;
V(mutex); // 之前为0就唤醒
V(full); // 之前为空就唤醒
}
Consumer() {
P(full); // 缓冲区空没有, 空就停
P(mutex);
读入out; 从文件中的out位置读出到item; 打印item;
V(mutex);
V(empty);
}
信号量临界区保护
因为竞争条件(和调度有关的共享数据语义错误), 因为时间片的顺序是不确定的. 左图是错的, 右图是对的. 所以需要给empty上锁, 左图中的P2有关代码就只能在empty = P1.register;执行完之后再执行. 生产者P1和生产者P2的empty--是临界区(一次只允许一个进程进入的该进程的那一段代码). 修改信号量的这段代码必须是临界区, 加以保护. 进入区/退出区的设计就尤为重要, 保证进程间的约束关系互斥. 对于好的临界区保护, 应尽快使一进程进入临界区(有空让进), 并且从进程发出进入请求到允许进入不能无限等待(有限等待).

结合**标记(flag)和轮转(turn)**两种思想, 就有了Peterson算法. 保证有空让进和有限等待. 如果只有flag, 可能会出现无限等待(flag[j] = true;先被执行). 如果只有turn, 那一个进程完成后该进程就不能再次进入.

扩展到多个进程, 就需要面包店算法. 每个进程都获得一个序号, 序号最小的进入(轮转). 进程离开时序号为0, 不为0的
序号即标记(标记). 满足互斥进入/有空让进/有限等待. 问题是比较麻烦.

从硬件上限制会比较简单, 用cli()从硬件上限制调度, 退出临界区再用sti()打开调度, 每次只能有一个进程进入临界区, 这就是开关中断. 但是对多CPU(多核), 这种方法就不行了, 因为他无法阻止其他CPU的进程调度. 那么只能用硬件原子指令, 其中的指令会一次执行完, 它保证信号量这个值被锁上, 即使是多CPU也可以保证锁.
信号量的代码实现(todo)
死锁处理
如果先执行生产者, mutex从1到0, 但是现在空闲缓冲为0, 那么生产者阻塞, 又因为mutex为0, 消费者进入时mutex从0到-1, 也阻塞. 多个进程这样互相等待就造成了死锁.
死锁有4个必要条件(可以用堵车来想象):
- 互斥使用(Mutual exclusion), 这是资源的固有特性
- 不可抢占(No preemption), 资源只能自愿放弃, 这也是资源的固有特性
- 请求和保持(Hold and wait), 进程必须占有资源, 再去申请
- 循环等待(Circular wait), 在资源分配图中存在一个环路
死锁处理方法也有4种:
- 死锁预防, 破坏死锁出现的条件
- 死锁避免, 检测每个资源请求, 如果造成死锁就拒绝
- 死锁检测+恢复, 检测到死锁出现时, 让一些进程回滚并让出资源
- 死锁忽略, 假装没有出现死锁, 普通PC可以用万能的重启
死锁预防
在进程执行前一次性申请所有需要的资源, 不会占有资源再去申请其它资源. 这就会造成资源的浪费, 而且预测死锁的编程很困难. 虽然可以把资源类型进行排序, 简化编程, 但是这仍然造成资源浪费.
死锁避免
判断此次请求是否引起死锁. 如果系统中的所有进程存在一个可完成的执行序列(没有死锁),则称系统处于安全状态. 对应的银行家算法如下, 通过循环去计算合适的序列. 时间复杂度是$O(mn^{2})$. 如果当前申请没有安全序列, 该进程就不能执行.
int Available[1..m]; //每种资源剩余数量
int Allocation[1..n,1..m]; //已分配资源数量
int Need[1..n,1..m];//进程还需的各种资源数量
int Work[1..m]; //工作向量
bool Finish [1..n]; //进程是否结束
Work = Available; Finish[1..n] = false;
while(true){
for(i=1; i<=n; i++){
if(Finish[i]==false && Need[i]<=Work){ // 需要的小于工作的
Work = Work + Allocation[i]; // 分配的资源被释放
Finish[i] = true; break;
}
else {goto end;}
}
}
End: for(i=1;i<=n;i++)
if(Finish[i]==false) return “deadlock”;
下图是实例, 因为每次申请都要进行一次银行家算法, 代价过大. 如果P0尝试申请(0, 2, 0), 剩下的资源是(2, 3, 0), 那么如果给P0分配资源, Allocation/Need/Available对应(0, 3, 0)/(7, 2, 3)/(2, 1, 0). 发现其他所有进程都无法满足, 则此次申请被拒绝. 这里的Allocation可以看做银行已经贷出的钱, Need相当于每个进程(客户)还需要的钱, Available是银行剩下的钱. 下图中初始资源是(3, 3, 2), 则安全序列为13240.
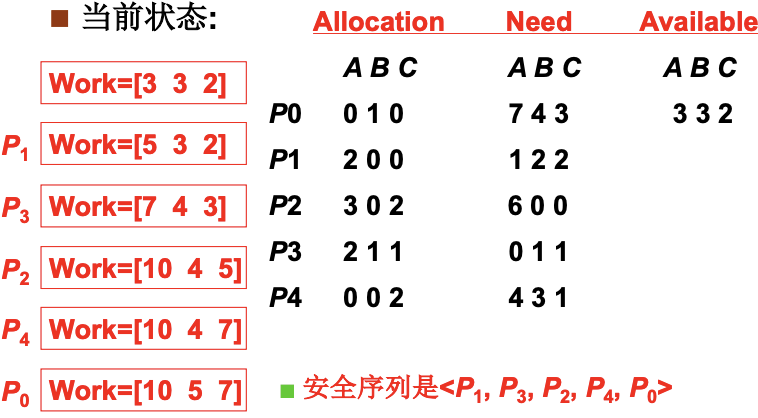
死锁检测+恢复
定时检测或者是发现资源利用率低时检测. 避免每次申请都要执行银行家算法, 发现了问题再处理, 并回滚. 但是回滚是很难的. 所以才会有死锁忽略, 对一般的PC(本来出现死锁的概率低)直接重启就可以了, 所造成代价小.
参考
- 操作系统-李志军
- 配套实验
- 汇编语言-王爽
comments powered by Disqus