内存使用与分段
回顾冯诺依曼的取址执行, 计算机取址执行, 也就是将程序(从磁盘)放到内存中,PC指向开始地址. 如果有下面的代码, call 40所在的位置是0地址, _main所在的位置是40, 那么call 40就调用了_main所对应的指令. 然而这要求IP指针最初指向的call 40就在0, 显然不灵活, 所以程序中的地址40应该是相对(逻辑)地址. 在执行时, 会修改程序中的地址, 使其成为物理地址, 这就是重定位. 如果在编译时重定位的程序只能放在内存固定位置, 防止某段地址在编译后被使用了, 载入时重定位的程序一旦载入内存就不能动了, 把相对地址加上空闲内存的基值, 这就更加灵活了.
...
_main: mov [300], 0
...
call xx
call 40
为了充分利用内存, 进程会在内存和磁盘中交换(swap), 也就是说即使程序已经载入了, 他们的物理地址还是会改变的, 所以重定位最合适的时机应该是运行时重定位(地址翻译).
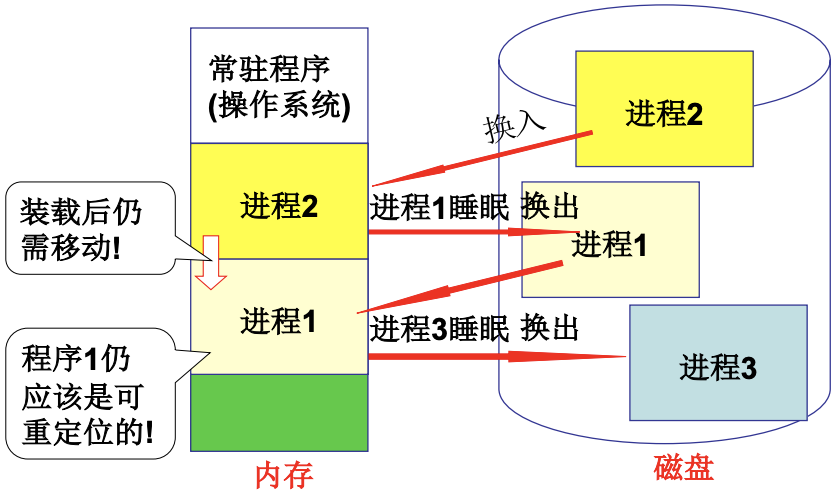
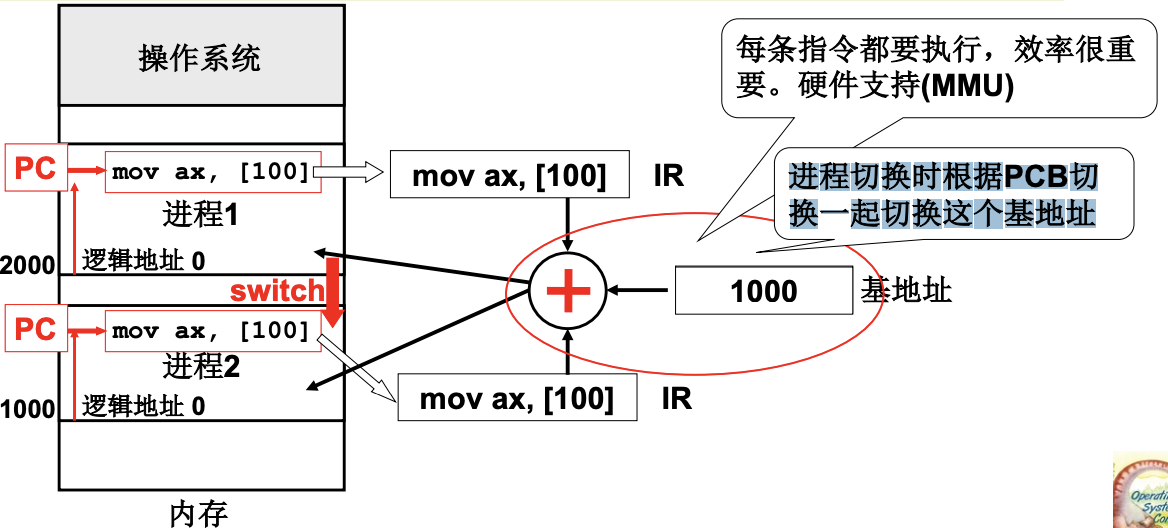
在PCB中存储基地址(base), 物理地址就是base+offset(逻辑地址). 进程切换时根据PCB切换一起切换这个基地址, 每次取址执行都要计算真实的物理内存地址. 下图中的两个进程都有mov ax, [100]指令, 但实际上对应着2100和1100.
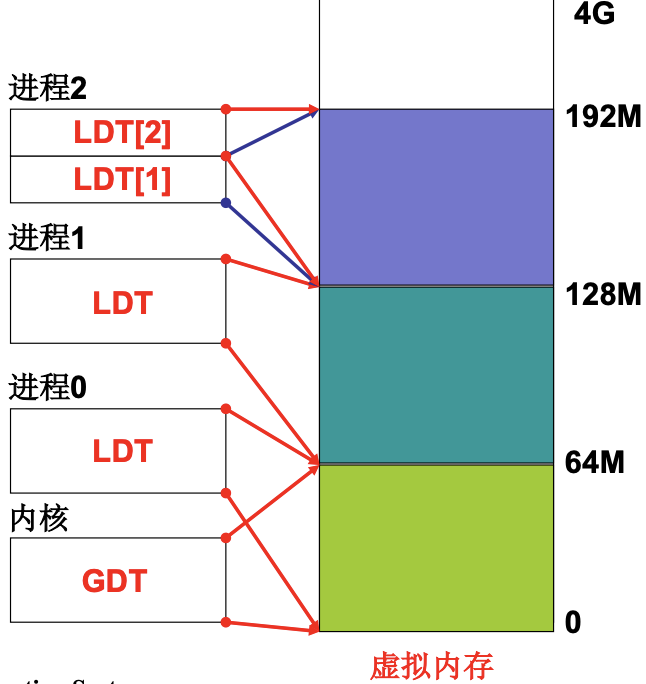
整个程序不是一起载入内存中的, 而是由若干部分(段)组成, 将各段分别放入内存. 每个段有各自的特点和用途. 比如有些库只读(写保护), 有些库可写, 对不同的库, 用户都可独立地考虑. 这里我也联想到了JVM, 栈空间如果只考虑自身, 那么实际上我们就可以扩展它本身而不考虑对其他如堆空间的影响(这只是我的猜测). 所以对同一个进程的不同段, 都有所对应的段的基值DS. 之前讲的GDT表所对应的就是os的段表, 而进程所对应的段表就是LDT表, 记录一些基值. 在程序分段进入内存之后, 就会找到段的基地址, 放在LDT表(存储在ldtr寄存机中)中并赋给PCB.
内存分区与分页
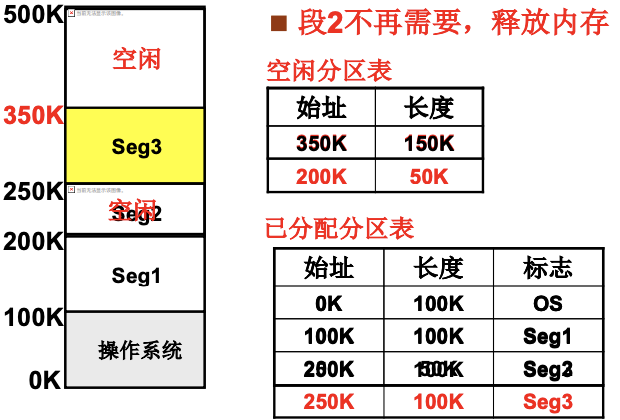
那么内存如何分割呢. 怎么找到内存中空闲的区域(分区)呢? 段的大小不能确定, 固定分区不够灵活, 所以需要可变分区, 如下图中的表, 包含了起始地址和分区长度. 如果有多个空闲分区, 该怎么选? 一般有首先适配(快), 最佳适配(快), 最差适配(可能就是首先适配的那一个区域). 如果段内存请求很不规则, 那么最佳适配就比较好.
实际的os中, 一般实际的物理内存是用的分页. 而分区针对的是虚拟内存, 在后面会见到. 分区下会有过多的内存碎片, 导致即使总空闲分区大, 但是每个空闲分区却不够, 这时候需要内存紧缩来使空闲分区合并, 但是这会花费大量时间. 所以把内存分页, 针对每个段内存请求,系统一页一页地分配给这个段. 如果一页大小是4k, 那么一个段最多就浪费4k.
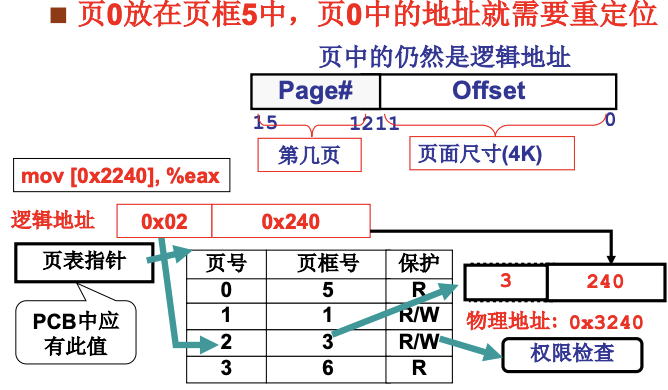
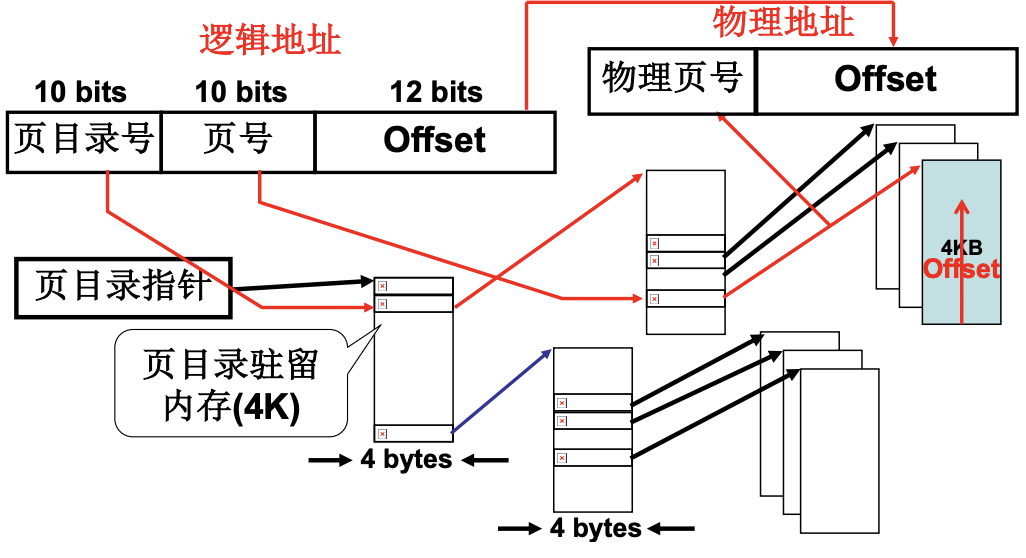
与段表对应, 分页就需要用到页表, 存储在每个进程的cr3中. 页中的地址依然是逻辑地址, 对于4k的页面, 如果逻辑地址是0x2240, 右移12位($1024*4=^{12}$)就是0x02, 这就是页号, 对应一个页框号, 后三位这个余数0x240就是偏移地址. 最后的物理地址就是0x3240.
多级页表与快表(Multilevel Paging)
为了提高内存空间利用率, 页应该小, 但是页小了页表就大了. 所以, 因为很多逻辑地址不会用到, 自然就想到在用到逻辑页时才加入页表项. 但是如果页表项不连续, 去查找页号就会很慢(通过访问内存本来就慢, 额外访问就更慢, 连续则直接算偏移多少就可以了). 所以就有了多级页表, 也就是页目录表+页表, 就像书分章节一样去实现快速查找. 空的页目录的映射/页表项就不用去记录, 节省空间. 但是多级页表也增加了访问的次数, 每多一级, 就要多访问一次内存.
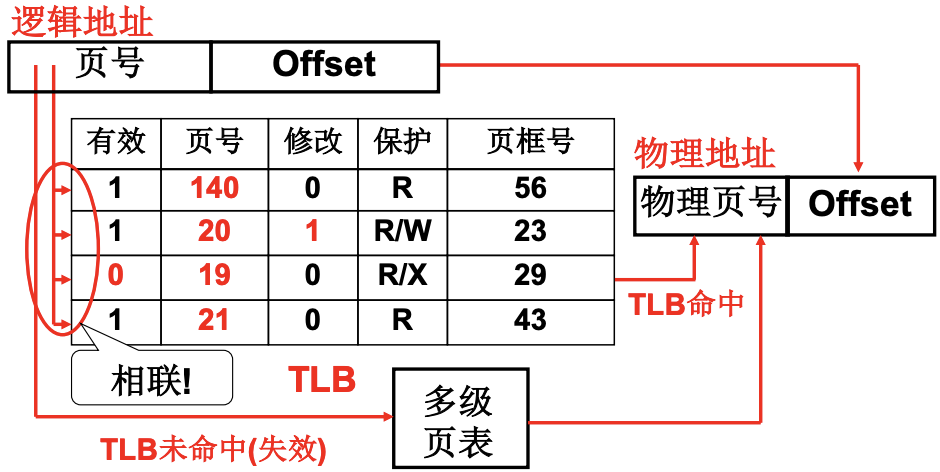
快表TLB可以记住最近使用的页表项. TLB是一组相联快速存储. 从硬件上就可以通过一次比对来找到物理地址. 题外话, 我感觉这种思想挺通用的, 就像DNS缓存一样, 用一点点额外的空间来换时间. TLB通常大小只有64到1024, 虽然小, 但是程序的地址访问存在局部性(循环/顺序结构), 逻辑页号通常就是那几个, 所以依然可以有比较好的命中率.
段页结合的实际内存管理
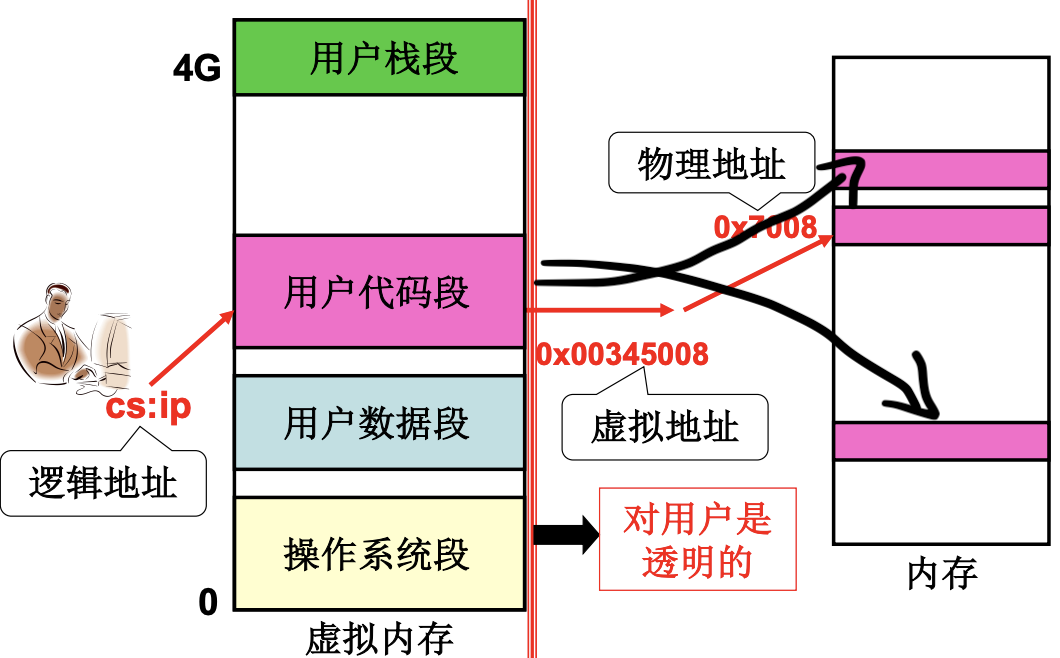
实际上, 程序希望用段而物理内存希望用页, 所以这两者需要结合在一起. cs:ip指向的逻辑地址指向虚拟内存的某一段, 而用户代码段指向物理内存的物理地址(一些页), 这样就把的代码放在了真实的内存.
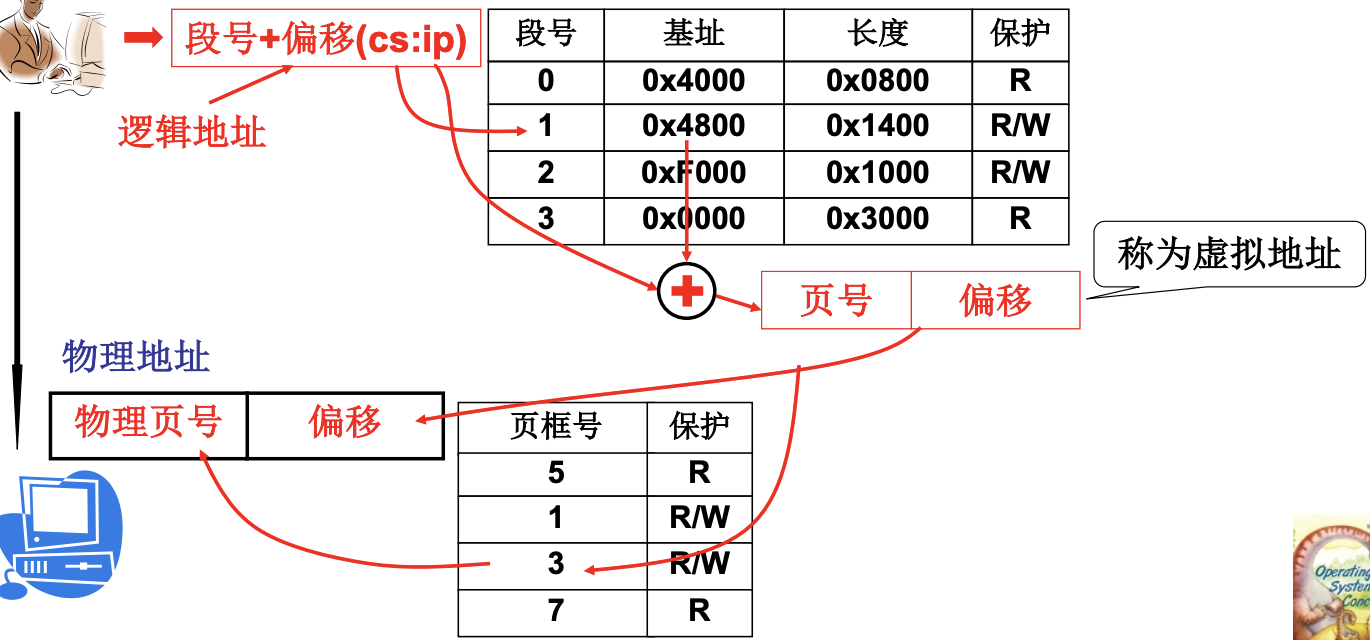
这种情况下如何重定位呢, 因为既分段, 又分页, 那么就需要两个表. 从用户角度来看, 依然是使用段号+偏移. 从操作系统的角度看, 就是物理页号+偏移.
步骤(todo)
这一段还是有点迷惑, 真正理解需要做实验, 这里我写了一点大致的理解.
在linux/kernel/fork.c中, 分配虚拟内存, 建段表. linux0.11分段都是64M的, 并且不重叠, 较为简单.
int copy_process(int nr, long ebp, ...) { ... // 复制进程
copy_mem(nr, p); ...
}
int copy_mem(int nr, task_struct *p) {
unsigned long new_data_base;
new_data_base=nr*0x4000000; // 64M * nr(进程id), 分割虚拟内存, 64M为一段
set_base(p->ldt[1],new_data_base); // PCB的ldt被赋值, 被分段, 进程切换段表也要切换
set_base(p->ldt[2],new_data_base); // 代码段/数据段
}
分配内存/物理页(父进程已经分配好, 这里复制即可), 建页表. 因为之前的虚拟地址是不重叠的, 所以可以用相同的一个页表.
int copy_mem(int nr, task_struct *p) {
unsigned long old_data_base;
old_data_base=get_base(current->ldt[2]);
copy_page_tables(old_data_base,new_data_base,data_limit); // 传递虚拟地址, 分配/复制内存
}
int copy_page_tables(unsigned long from,unsigned long to, long size) {
from_dir = (unsigned long *)((from>>20)&0xffc); // from是来自父进程的32位虚拟地址(10bits页目录号, 10bits页号, 12bit soffset).
// 右移20位相当于右移22位乘以4, 因为右移22位得到的是目录号, 乘以4byte才能得到当前项
to_dir = (unsigned long *)((to>>20)&0xffc);
size = (unsigned long)(size+0x3fffff)>>22;
for(; size-->0; from_dir++, to_dir++) { // size: 有多个页目录(64M下的多个4M页目录), to_dir就是子进程页目录, 给子进程页目录分配实际内存
from_page_table=(0xfffff000&*from_dir);
to_page_table=get_free_page(); 分配物理内存页(让页目录指向实际页), 这体现多级页表的优势, 如果没有映射就不分配物理内存页
}
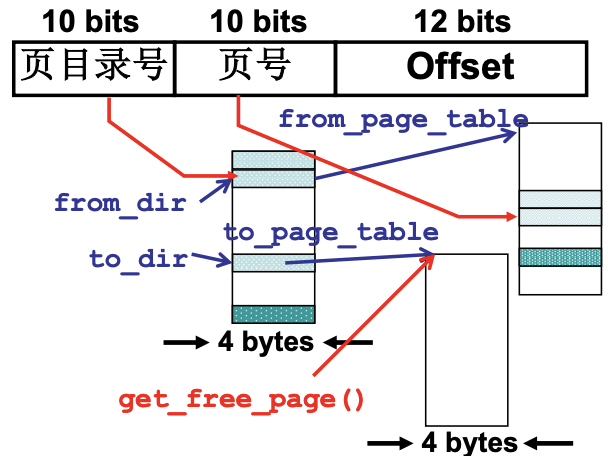
页目录新建好了, 就需要把的页实际内容拷贝过来. 让子进程和父进程对应的位置指向相同页.
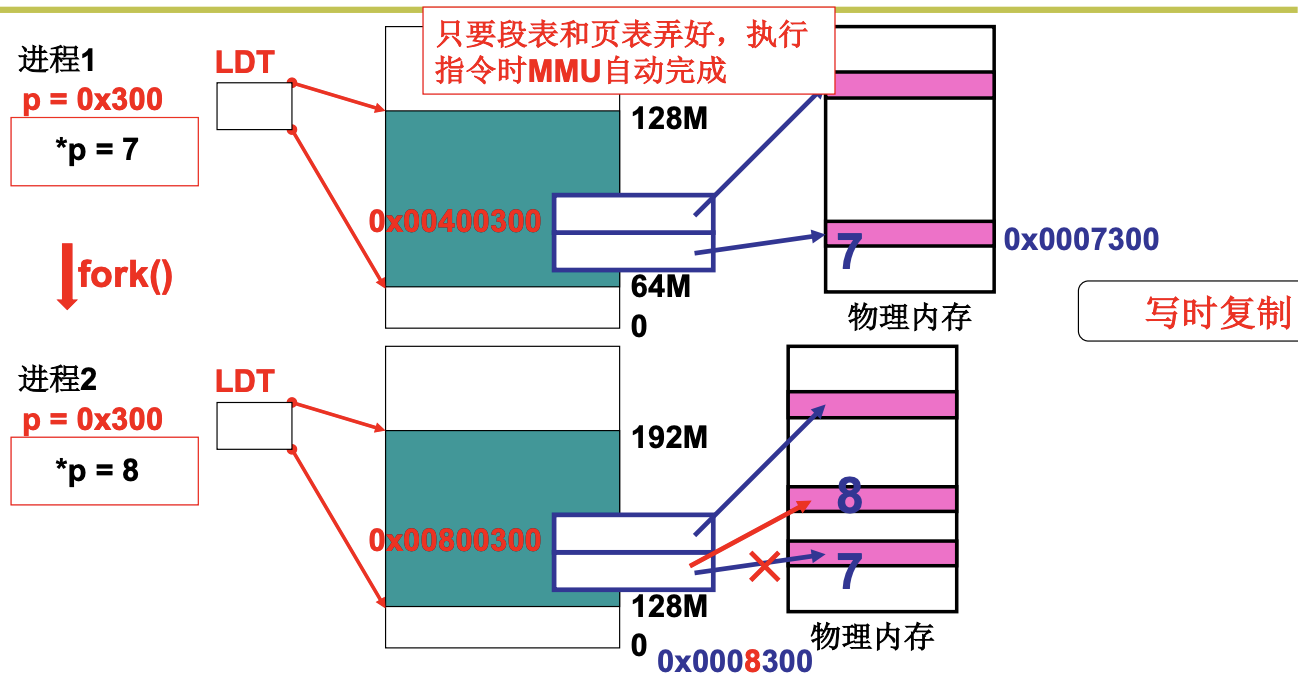
for(;nr-->0;from_page_table++,to_page_table++) {
this_page = *from_page_table; // 把from_page_table中的内容(页表项)取出
this_page&=~2; //只读
*to_page_table=this_page;
*from_page_table=this_page;
this_page -= LOW_MEM; this_page >>= 12;
mem_map[this_page]++;
}
1是父进程, 2是子进程. LDT表的基值从0x00400到0x00800. 因为只读, 保证了子进程不会写到7的位置, 而是新建页写到8的位置. MMU是内存管理单元. 通过重定位来真正使用内存.
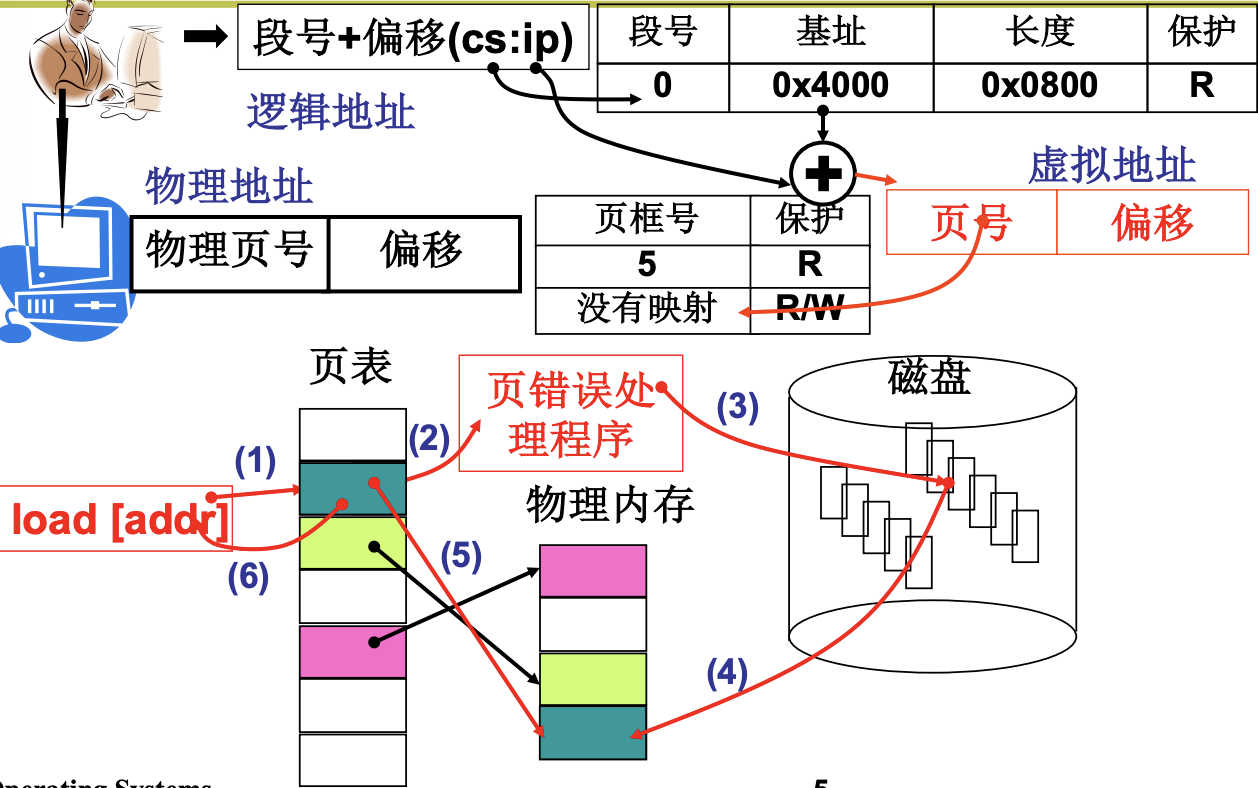
内存换入-请求调页
对用户来说, 能看到的值规整的虚拟内存, 虚拟内存比物理内存大是怎么实现的呢. 那就需要换入换出. 虚拟内存(磁盘)就像是仓库, 而物理内存就像是店面. 所以有换入换出, 才会有虚拟内存. 执行代码时, 如果发现页表对应项没有在内存中, 那么就需要把需要的页换入, 这里进行一个中断, 步骤如下图.
内存换出
物理内存是有限的, 所以并不能总是获得新的页, 那么就需要把页换出. 那么怎么选择淘汰的页呢.
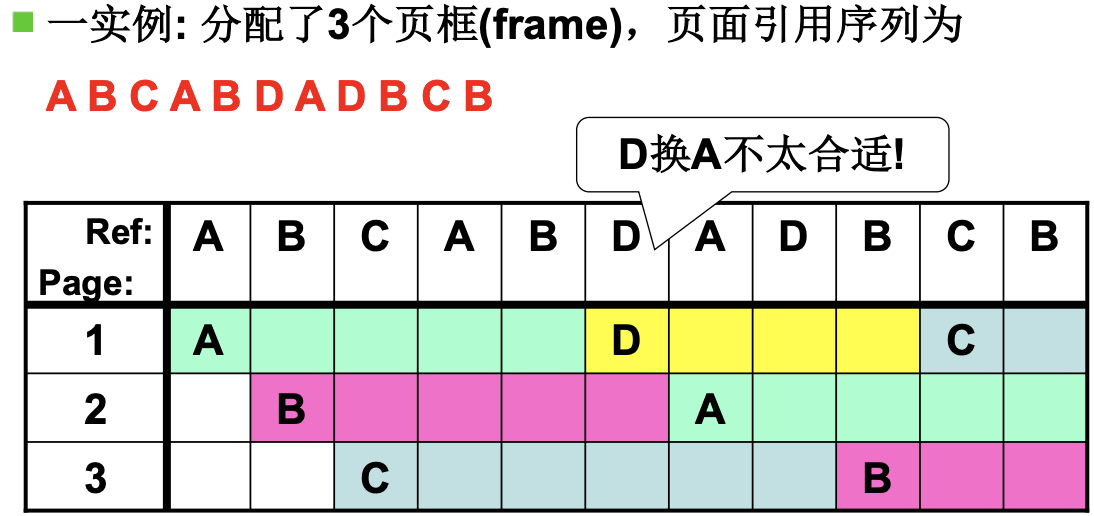
基础的是FIFO, 如下. 产生了7次缺页, D换A不合适, 理想的是换C.
就有了MIN, 选最远将使用的页淘汰, 这是最最优的, 但是预测未来是不可能的.
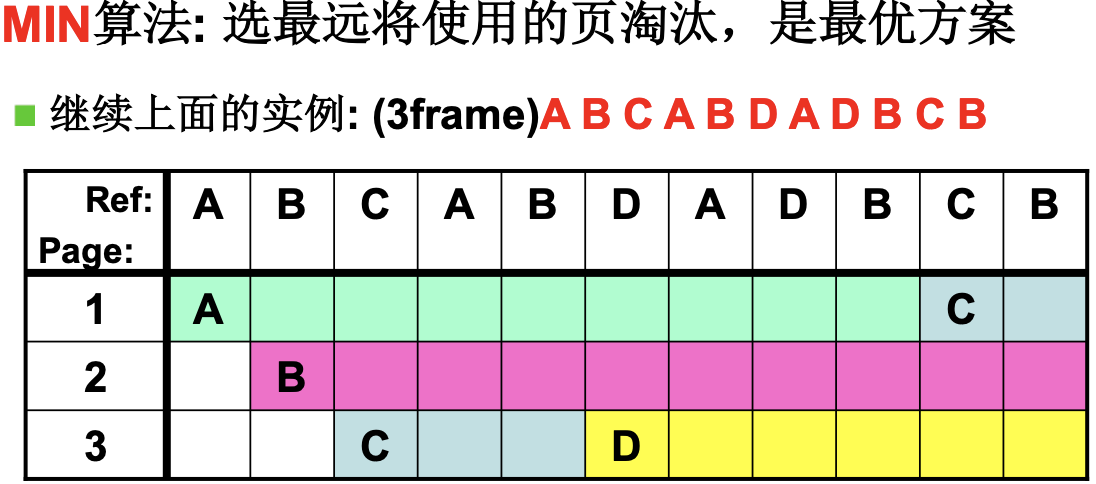
所以要通过之前的历史来预测将来, 就有了LRU页面置换: 选最近最长一段时间没有使用的页淘汰(最近最少使用). 实际上在这个例子和MIN的图一样, 只会产生5次缺页.
从实现来看, 如果用时间戳, 也就是给每页都维护一个时间戳, 每次加1, 每执行一条指令都需要修改时间戳, 实现代价过大. 如果用用页码栈, 每次地址访问都需要修改栈, 实现代价依然太大. 这两种方法都是准确实现, 在实际系统中都不太实用, 所以在操作系统中要用近似实现.
给每个页加一个引用位, 每次访问一页时, 硬件自动设置该位. 是1时清0, 并继续扫描, 本来就是0时淘汰该页. 也就是说从最近最少访问近似成了最近没有访问. 这就是Clock算法.
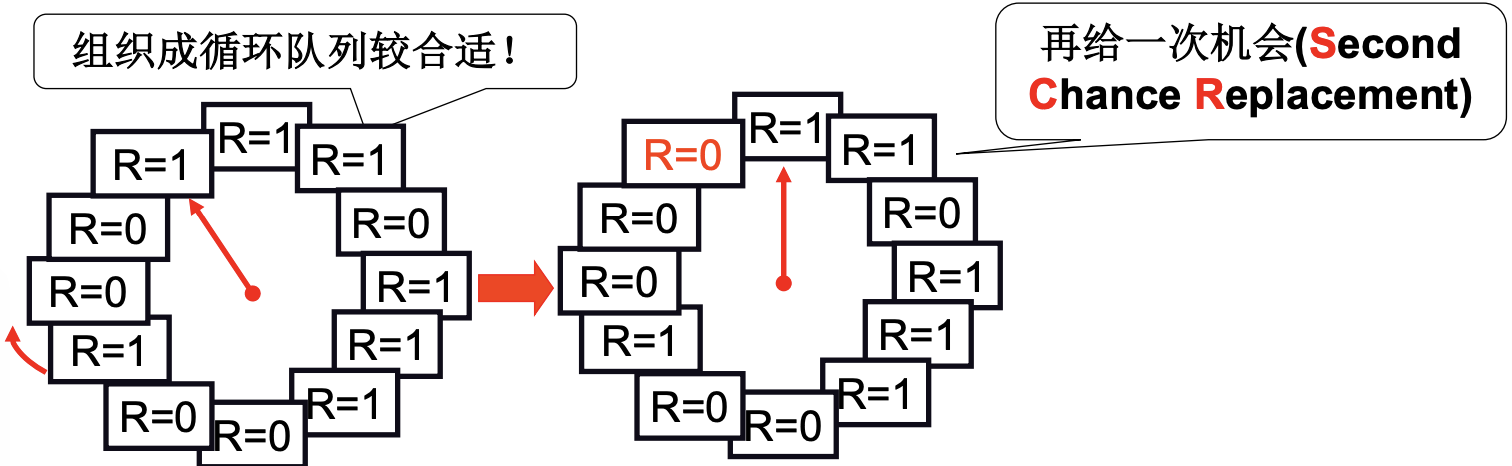
但是如果缺页少, 就会让几乎所有R=1, 造成这个现象的原因是记录了太长的历史信息. 所以概要一个移动速度快的扫描指针用来定时清除R位. 而之前的指针移动速度慢, 用来选择淘汰页. 两个指针也更像clock了.
当进程逐渐变多的过程中, CPU的利用率会上升, 但是当进程数量达到某个值的时候, CPU的利用率会急剧下降, 这个现象叫颠簸(thrashing). 产生颠簸的原因是进程过多导致分到的页少, 进程就总是在等待调页完成, CPU一直不工作. 所以分配进程的页框数量也需要好好选择.
参考
- 操作系统-李志军
- 配套实验
- 汇编语言-王爽
comments powered by Disqus