I/O与显示器
使用外设通常就是CPU向外设发指令, 当外设完成后做中断处理程序. 有单片机背景的朋友应该会很熟悉这种模式, 通过i2总线, spi总线等等使挂载在总线上的设备或者传感器工作. 而对于计算机来说就是PCI总线. 向设备控制器的寄存器写很麻烦, 所以操作系统要给用户提供一个简单视图: 文件视图. 总的来说就是3步: out发出指令, 形成文件视图, 设备中断.
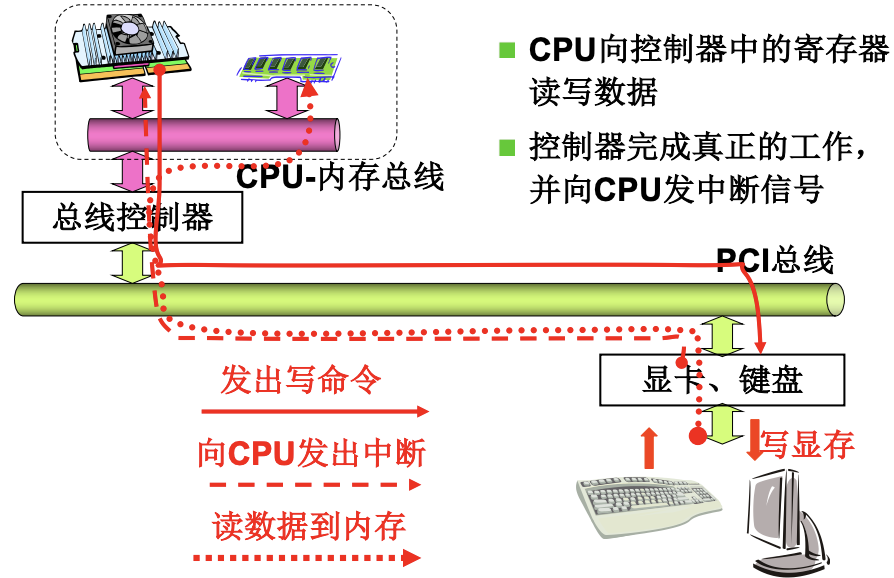
操纵外设的例程如下, 会发现有write(), 而操作系统会为用户提供统一的接口: open/read/write/close. 而不同的设备对应不同的设备文件/dev/xxx, 这样就可以区分不同的设备了. 这也体现出了文件视图.
int fd = open(“/dev/xxx”);
for (int i = 0; i < 10; i++) {
write(fd,i,sizeof(int));
}
close(fd);
这一节讲显示器, 所以从printf让显示器输出到out开始这个故事. printf先把格式化的输出存储在缓存buf中, 然后执行write(1, buf, ...). write这个统一的接口会根据不同的设备(文件)进行分支. 1这个数字决定了显示到显示器. write的系统调用就是下面的sys_write.
int sys_write(unsigned int fd, char *buf, int count) { // fd是找到file的索引
struct file* file;
file = current->filp[fd]; // current是当前进程, filp就是当前进程PCB中的数组
inode = file->f_inode; // 该文件的一个信息(往哪里输出)
fd=1的filp来自PCB, 而进程是从父进程拷贝的(int copy_process(...)中可以看到*p = *current),那么一开始父进程怎么开始的? 如下:
void main(void) {
if(!fork()){
init();
}
}
void init(void) {
open(“dev/tty0”,O_RDWR,0); // 中断设备dev/tty0
dup(0); // 拷贝
dup(0);
execve("/bin/sh",argv,envp)
}
上面的open的系统调用sys_open根据文件名读入文件的inode(文件信息), 而子进程也找到了这个inode, 所以fd=1就可以找到这个设备信息inode. 总结成一张图如下:
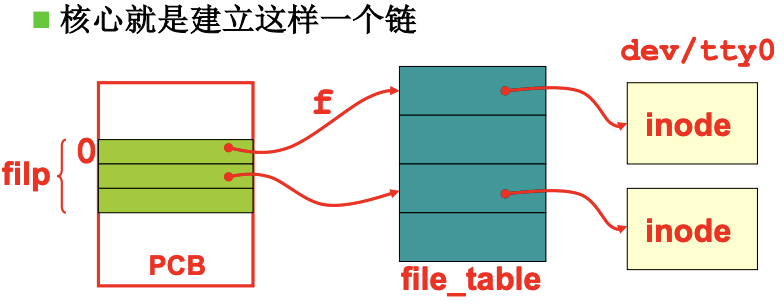
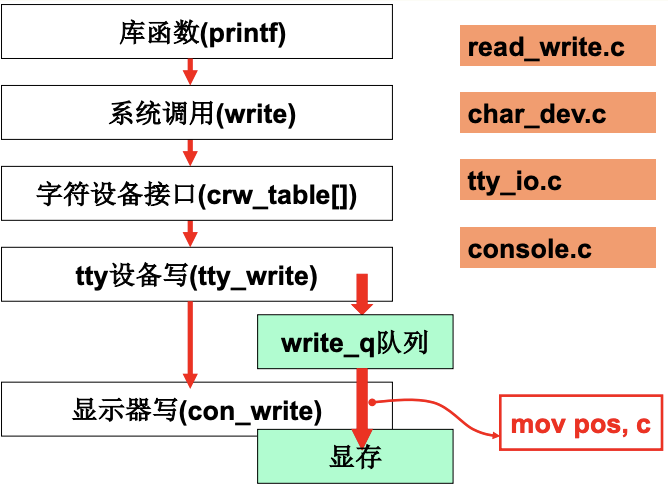
真正屏幕的输出会根据inode判断出/dev/tty0是字符设备(依然在sys_write中), 并执行rw_char, 通过函数指针在crw_table中找到对应的函数static int rw_ttyx(int rw, unsigned minor, char *buf, int count), 并执行其中的tty_write函数.
这个tty_write从用户缓存读入, 放入输出的队列&tty->write中. 执行tty->write(tty)中的con_write进行输出, 最终对应汇编命令mov pos输出到显存, 用mov不用out是因为i/o设备存储器的地址是统一编址的, 如果是独立编址就用out.
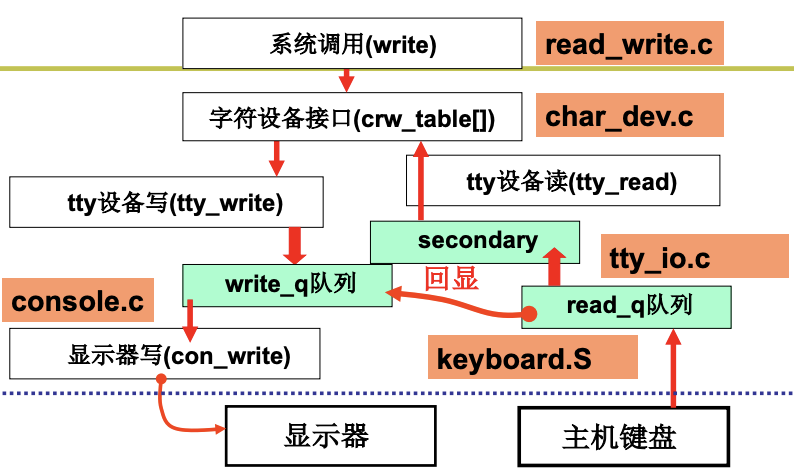
键盘(todo)
生磁盘的使用
接下来都讲磁盘, 和显示器和键盘一样, 从out到送数据, 到向CPU发中断. 首先从生磁盘开始. 磁盘i/o也分为三步:
- 寻道, 移动磁头到某一磁道
- 旋转, 旋转磁盘到对应扇区
- 传输, 磁生电让内存读数据, 电生磁向磁盘写数据
所以直接读写磁盘要确认写柱面C(多个磁盘), 磁头H, 扇区S, 缓存位置. 从磁盘的角度看就是CHS这个三维的地址. 计算CHS的工作交给os.

通过盘块号读写磁盘(一层抽象)
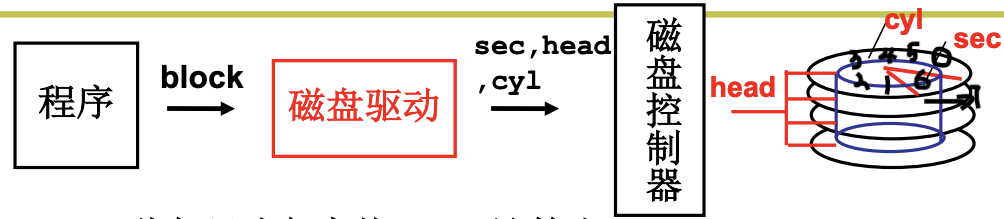 如上图, 我们希望用盘块号来计算CHS. 因为磁盘访问时间 = 写入控制器时间 + 寻道时间(移动磁壁: 8~12ms) + 旋转时间(7200转: 半周4ms) + 传输时间(50M/s: 0.3ms). 更多的时间都浪费在呢移动磁壁的机械运动上. 所以我们希望扇区(盘块)是连续的来减少寻道时间. 盘块是几个连续的扇区, 因为相比传输时间, 寻道时间和旋转时间是慢的吗那么如果一次多读写一些数据, 就可以加快磁盘访问时间. 虽然因为这会造成碎片使空间利用率下降. 所以这又是一个时间和空间的tradeoff. 盘块号的计算公式是$block=C\times(Heads\times Sectors) + H\times Sectors + S$.
如上图, 我们希望用盘块号来计算CHS. 因为磁盘访问时间 = 写入控制器时间 + 寻道时间(移动磁壁: 8~12ms) + 旋转时间(7200转: 半周4ms) + 传输时间(50M/s: 0.3ms). 更多的时间都浪费在呢移动磁壁的机械运动上. 所以我们希望扇区(盘块)是连续的来减少寻道时间. 盘块是几个连续的扇区, 因为相比传输时间, 寻道时间和旋转时间是慢的吗那么如果一次多读写一些数据, 就可以加快磁盘访问时间. 虽然因为这会造成碎片使空间利用率下降. 所以这又是一个时间和空间的tradeoff. 盘块号的计算公式是$block=C\times(Heads\times Sectors) + H\times Sectors + S$.
Heads是磁头数(如果上图是单面磁盘就是4), Sectors是一个磁盘上的扇区数.
多个进程通过队列使用磁盘(两层抽象)
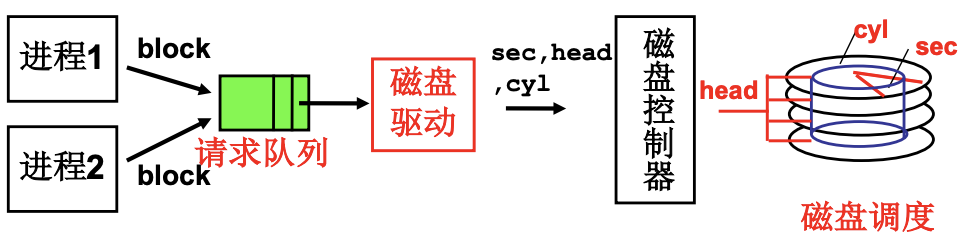
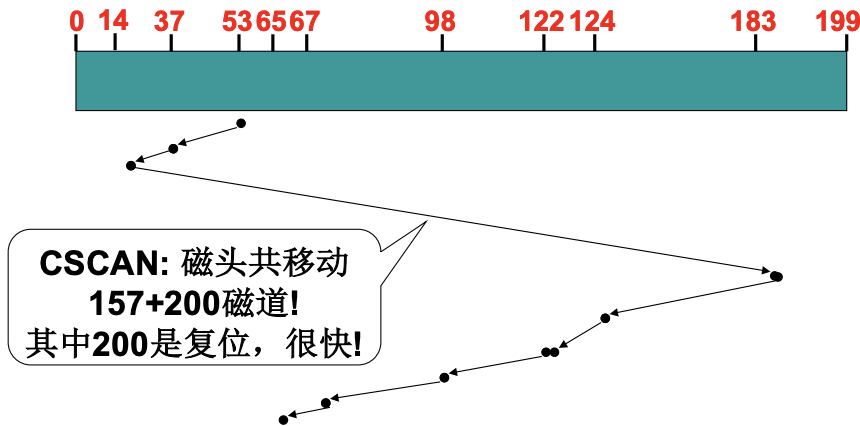
多个进程请求磁盘需要请求队列, 因此需要合理的调度. 对于FCFS磁盘调度算法, 如果请求队列是98, 183, 37, 122, 14, 124, 65, 67并且磁头开始在53. 磁头就需要在柱面之间不断移动, 非常慢. 那么就考虑在移动过程中处理请求, 于是有了SSTF磁盘调度, 短寻道优先(Shortest-seek-time First), 减少了寻道的时间.
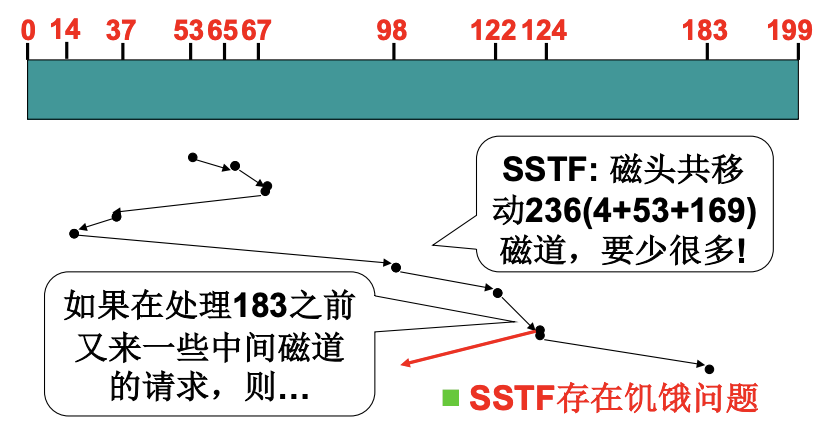
因为请求通常集中在中间柱面, 尤其是读写迅速的场景, 对于SSTF, 磁头就很难移动到远处, 容易造成饥饿. 而SCAN磁盘调度就可以解决饥饿问题, 也就是SSTF并且中途不回折.
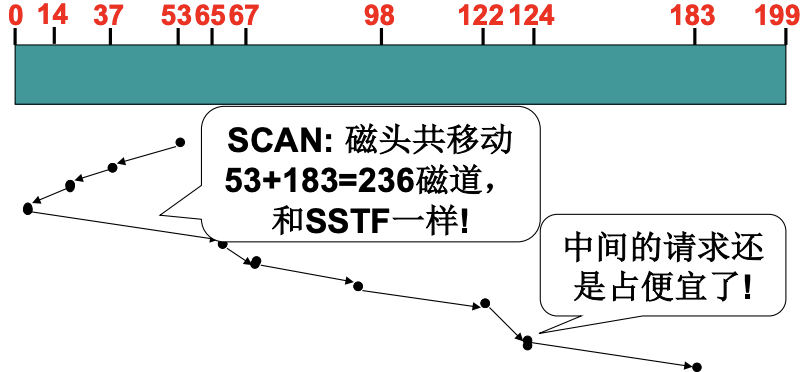
进一步C-SCAN磁盘调度(电梯算法), 让磁头直接从一端到另一端.
static void make_request()
{
req->sector=bh->b_blocknr<<1; // 盘块号转换为扇区号
add_request(major+blk_dev,req); // 将请求放在队列
}
static void add_request(struct blk_dev_struct *dev, struct request *req) {
struct requset *tmp=dev->current_request;
req->next=NULL; cli(); //关中断(互斥), 临界区保护
for(;tmp->next;tmp=tmp->next) // 从前往后扫描
// tmp < req < next(req插到中间) 或 tmp >= next && req < next(折回去) , 形成电梯队列
if((IN_ORDER(tmp,req)||!IN_ORDER(tmp,tmp->next)) && IN_ORDER(req,tmp->next)) break;
req->next=tmp->next; tmp->next=req;
sti(); //临界区保护
}
// 因为C主导, 等价于根据柱面号比较. sector = C*(Heads*Sectors) +H*Sectors + S. 也就是前面图片中的数字
#define IN_ORDER(s1, s2) \
((s1)->dev<(s2)->dev)||((s1)->dev == (s2)->dev\
&& (s1)->sector<(s2)->sector))
综上, 生磁盘使用分以下步骤:
- 进程"得到盘块号", 算出起始位置扇区号(sector)
- 用扇区号make req(涉及内存缓冲区), 用电梯算法add_request, 放到请求队列
- 进程sleep_on, 让硬件工作
- 磁盘中断处理
- do_hd_request(磁盘驱动), 算出cyl, head, sector
- hd_out调用outp(…)完成端口写, 最后唤醒进程, 数据已经到了内存缓冲区
从生磁盘到文件(Files-cooked Disks)
实际上用盘块号访问磁盘依然麻烦, 所以引入文件, 对磁盘进行第三次抽象. 实际上, 文件就是字符序列, 或者叫字符流. 而文件建立了字符流到盘块集合的映射关系. 简单地说, 就是要从字符流, 算出盘块号i
如果用连续结构来实现文件, 甚至需要在FCB中记录文件对应的起始块, 因为盘块大小确定, 做一个简单的除法就知道对应哪个盘块集合了. 连续结构就像数组一样, 读写方便但不适合动态增加. 所以可以用链式结构来实现文件. 文件增删更加容易, 但是顺序访问就慢了.
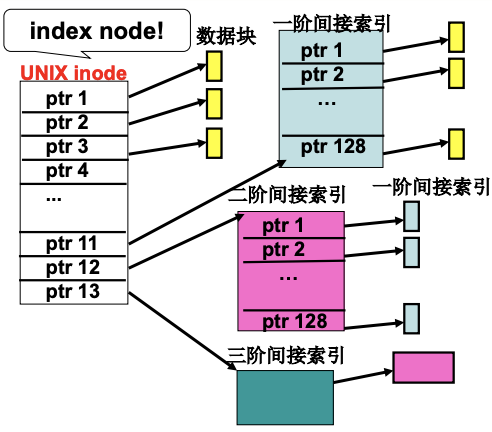
实际上操作系统使用的是索引(多级)结构, 是连续和链式分配的有效折衷. 根据inode找到文件所对应的索引块, 根据字符流的位置(如200-212)找到其对应索引块的位置, 再读就可以找到实际的内容了. 扩展的时候也可以直接找到空闲区域, 放到索引块中.
代码实现
通过文件使用磁盘:
int sys_write(int fd, const char* buf, int count) { //文件描述, 内存缓冲区, 字符个数
struct file *file = current->filp[fd];
struct m_inode *inode = file->inode;
if(S_ISREG(inode->i_mode))
return file_write(inode, file, buf, count);
}
file是起始位置, count是长度. 根据inode的表得到索引号, 找到块号…
int file_write(struct m_inode *inode, struct file *filp, char *buf, int count) {
//用file知道文件流读写的字符区间
off_t pos;
if(filp->f_flags&O_APPEND)
pos=inode->i_size; // 如果是追加, pos放在文件最后
else pos=filp->f_pos; //f_pos就是读写的位置, 放在上次读写的位置
while(i<count){
block=create_block(inode, pos/BLOCK_SIZE); //算出对应的块
bh=bread(inode->i_dev, block); //放入电梯队列
int c=pos%BLOCK_SIZE; char *p=c+bh->b_data;
bh->b_dirt=1; c=BLOCK_SIZE-c; pos+=c; //增加pos, 读写位置后移
... while(c-->0) *(p++)=get_fs_byte(buf++); //一块一块拷贝用户字符
brelse(bh); //释放写出
}
filp->f_pos=pos;
}
m_inode是设备文件的inode
struct m_inode { //读入内存后的inode
unsigned short i_mode; //文件的类型和属性
...
unsigned short i_zone[9]; //指向文件内容数据块
struct task_struct *i_wait;
unsigned short i_count;
unsigned char i_lock;
unsigned char i_dirt; ...
}
int sys_open(const char* filename, int flag) {
if(S_ISCHR(inode->i_mode)) //字符设备 {
if(MAJOR(inode->i_zone[0])==4)
current->tty=MINOR(inode->i_zone[0]);
}
}
目录与文件系统
第四层抽象, 之前是一个文件对应盘块号. 而现在要一些文件对应整个磁盘. 对用户来说, 磁盘就是一个抽象的目录树. 一个硬盘在不同的机器上, 都会表示为目录树的一部分.
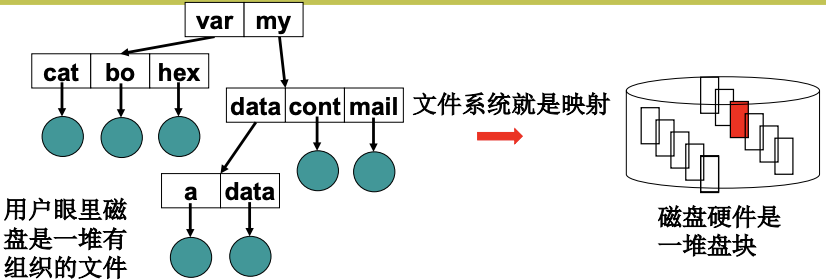
如果有了目录/my/data/a, 那么要去定位a, 也就是要得到文件a的FCB. 多层的每个目录项只用存放文件名和FCB的地址, 根据这个"地址"就可以找到FCB. 根据这个FCB的数据块又能找到下一层的目录项. 这里的"地址"实际上对应的是FCB数组中的位置. 除此之外, 磁盘还要存放一些信息.
- 引导块: 通常固定, 引导扇区
- inode位图: 哪些inode空闲, 哪些被占用.
- 盘块位图: 哪些盘块是空闲的, 硬盘大小不同这个位图的大小也不同.
- 空闲位图(位向量): 若向量为0011110011101, 表示磁盘块2, 3, 4, 5, 8, 9, 10, 12空闲
- 超级块: 记录inode位图/盘块位图有多大等信息, 读出了超级块就可以知道跟
/的位置.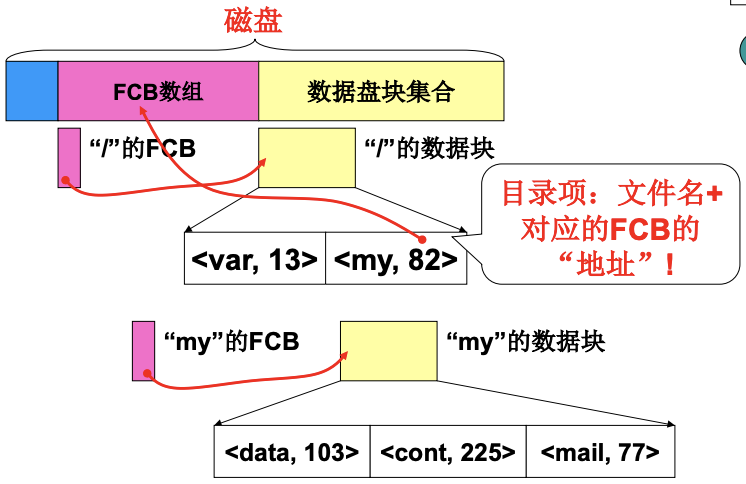
代码实现
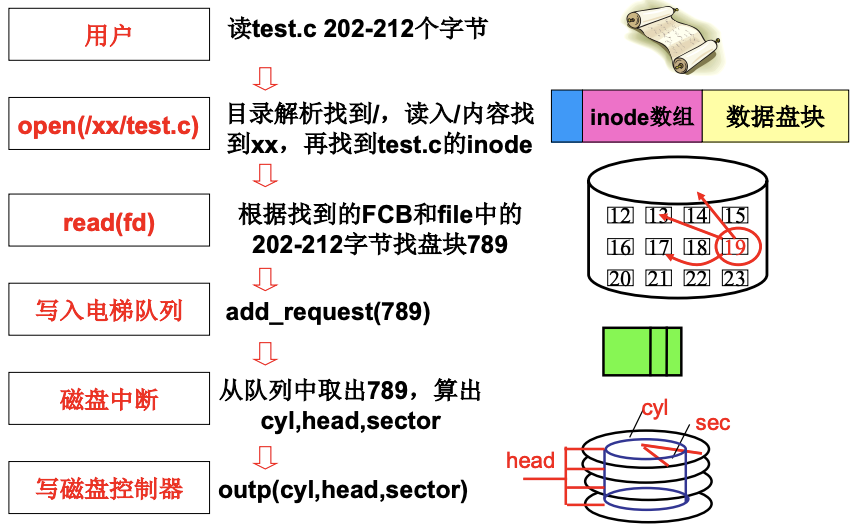 第一步第二步怎么目录解析呢. 实际就是讨论open. 从
第一步第二步怎么目录解析呢. 实际就是讨论open. 从sys_open到open_namei到*dir_namei. 最后到dir=get_dir(pathname);, 完成真正的目录解析.
static struct m_inode *get_dir(const char *pathname) {
if((c=get_fs_byte(pathname))==‘/’) {
inode=current->root; pathname++; //得到根目录FCB, 存下来, 以后的进程就可以拷贝了
} else if(c) inode=current->pwd;
while(1){
if(!c) return inode; //函数的正确出口
bh=find_entry(&inode,thisname,namelen,&de); //从目录中读取目录项
int inr=de->inode; //找到这一层的目录项中的索引节点号
int idev=inode->i_dev;
inode=iget(idev,inr); //根据目录项读取下一层inode
}
}
上面有inode=current->root;, 那么根目录怎么得到呢?
void mount_root(void) //在fs/super.c中
{
mi=iget(ROOT_DEV,ROOT_INO)); // #define ROOT_INO 1 根目录标号
current->root = mi;
}
如何用iget得到inode.
struct m_inode * iget(int dev, int nr) {
struct m_inode * inode = get_empty_inode();
inode->i_dev=dev; inode->i_num=nr;
read_inode(inode); //读inode
return inode;
}
static void read_inode(struct m_inode *inode) {
struct super_block *sb=get_super(inode->i_dev); // 读超级块
lock_inode(inode);
block=2+sb->s_imap_blocks+sb->s_zmap_blocks+(inode->i_num-1)/INODES_PER_BLOCK; //2指引导块和超级块, s_imap_blocks是inode位图, s_zmap_blocks是盘块位图, i_num要读的inode编号
bh=bread(inode->i_dev,block);
inode=bh->data[(inode->i_num-1)%INODES_PER_BLOCK];
unlock_inode(inode);
}

怎么读取目录项呢.
static struct buffer_head *find_entry(struct m_inode **dir, char *name, ..., struct dir_entry ** res_dir) {
int entries=(*dir)->i_size/(sizeof(struct dir_entry));
int block=(*dir)->i_zone[0]; //找到直接索引块
*bh=bread((*dir)->i_dev, block);
struct dir_entry *de =bh->b_data; //内存缓冲区中取出data
while(i<entries) { //entries是目录项数
if(match(namelen,name,de)) { //一个一个匹配, 找到了就返回
*res_dir=de;
return bh;
}
de++;
i++;
}
}
感谢老师.
参考
- 操作系统-李志军
- 配套实验
- 汇编语言-王爽
- 理解inode-阮一峰
comments powered by Disqus