协议管理
网络应用体系结构
有应用体系结构决定如何在端系统组织该应用程序. 包括客户-服务器体系结构和P2P体系结构.
- 客户-服务器体系结构: 主机总是打开服务其他客户主机的请求, 比如Web应用程序. 客户之间不会通信. 服务器具有固定, 周知的IP地址. 较大的应用会有配备大量主机的有数据中心.
- P2P: 对数据中心的服务器依赖小或者不依赖. 应用程序(对等方)在间断连接的主机之间直接通信. P2P具有自扩展性(self-scalability).
进程通信
相同端系统进程通信由操作系统确定. 不同的端系统进程通过端系统互相通信.
- 客户和服务器进程: 发起通信为客户, 等待联系的是服务器.
- 进程与计算机网络的接口. 进程通过socket的软件接口向网络发送报文或从网络接收报文. 应用开发对运输层的控制仅限于选择运输层协议/设定几个运输层参数.
- 进程寻址: 也就是寻找目的地地址, 需要主机的地址(IP地址)和定义在目的主机的接收进程的标识符(端口号).
供app使用的运输服务
选择运输层协议只有合不合适, 没有好不好. 我们从4个角度对app服务进行分类, 不要忘记这是针对运输层的.
- 可靠数据传输: app是否是loss-tolerant的, 比如多媒体应用丢失疑点数据就影响不大.
- 吞吐量: 网络路径的进程通信的场景中, 可用吞吐量就是发送进程能够向接收进程交付比特的速率. 有吞吐量要求的应用叫带宽敏感(bandwidth sensitive)应用, 比如多数的自媒体应用. 否则是弹性(elastic)应用, 如电子邮件等.
- 定时: 运输层提供实时保证, 比如打游戏就不能延迟太高.
- 安全性: 运输协议是否可以加密, 解密.
因特网的运输服务
- TCP: 面向连接, 可靠, 就有阻塞控制机制.
- UDP: 轻量, 不保证报文能到达接受进程, 也不保证顺序, 没有阻塞控制机制.

应用层协议
应用层协议只是网络应用的一部分, 协议规定了进行报文的通信, 定义了:
- 交换报文的类型, 如请求报文和响应报文
- 报文的类型和语法, 如报文中的各个字段和这些字段是如何描述的
- 字段包含信息的含义
- 进程何时已经如何发送报文, 对报文进行响应的规则
下面介绍各种网络应用及协议.
Web和HTTP
Web有按需操作的特点.
HTTP
Web的应用层协议是HTTP(HyperText Transfer Protoocol), HTTP由客户端程序和服务器程序共同实现. web页面由对象(包括html, jepg, java小程序等等)组成. html用过对象的url地址引用页面中的其他对象, 每个url由存放对象的服务器主机名和对象路径名组成. url地址http://www.bilibili.com/a/b.gif中, www.bilibili.com就是主机名, /a/b.gif就是路径名. web browser实现了客户端, web server实现了服务器端, 用于存储web对象, 每个对象由url寻址.
HTTP用TCP作为运输协议, 而HTTP本身是无状态协议, HTTP服务器不保存客户的信息.
非持续链接和持续链接
HTTP既可以非持续链接, 也可以持续链接.
- 非持续链接: 每个TCP链接在服务器发送一个对象后关闭, 每个TCP链接只传输一个请求报文和一个响应报文. 下面的步骤会产生11个TCP链接.

客户请求基本文件到该客户收到整个文件所花费的时间叫Round-Trip Time(RTT), 包括分组传播时延, 中间路由器和交换机上的排队时延和分组处理时延. 总的响应时间就是2*RTT+服务器传输HTML文件的时间. 也就是说每次连接都会有第一个发起连接的RTT.
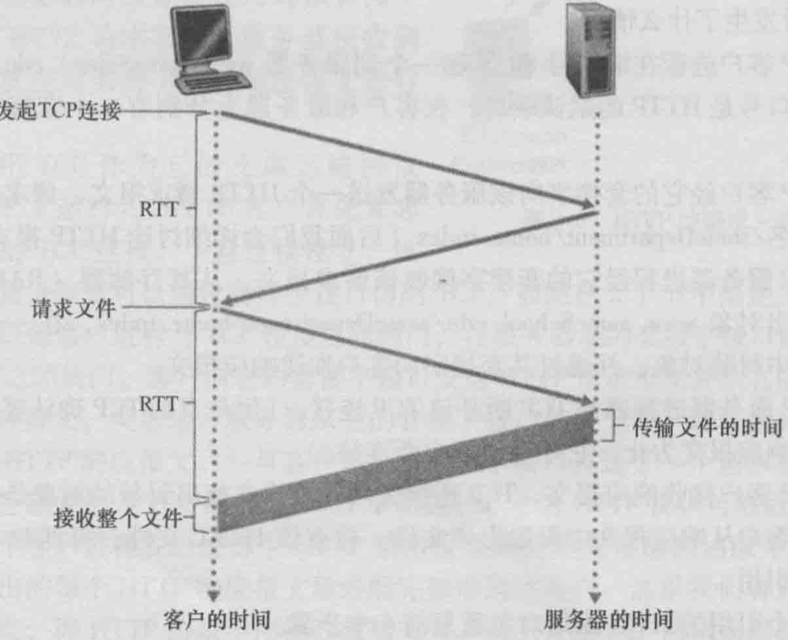
- 持续链接: 服务器在发送响应后保持TCP打开, 用过相同链接传输上面提到的HTML基本文件和10个图形, 如果一段时间不使用这条链接, 则HTTP服务器关闭连接.
HTTP报文格式
请求报文
GET /somedir/page.html HTTP/1.1
Host: www.someschool.com
onnection: close
User-agent: Mozilla/5.0
Accept-language: fr
每行由回车和换行符结束, 最后一行附加回车和换行符(我曾经在lab中因为不清楚这点debug了一下午), HTTP请求的第一行为请求行(request line), 后继的行叫做首部行(header line).
- 请求行包括方法字段(GET/POST/HEAD/PUT/DELETE), URL字段, HTTP版本字段; 图中的例子就是GET了/somedir/page.html这个对象.
- 首部行
Host: www.someschool.com, 看似没必要, 但是实际上是Web代理高速缓存所要求的.Connection: close就是非持续链接.User-agent: Mozilla/5.0指明了用户代理(向服务器发送请求的浏览器类型).Accept-language: fr首部行表示用户想要法语.
下图就是请求报文的通用格式, 后面有个实体主体entity body. 用GET方法时为空, 可是当用户提交表单时常常用POST方法, 而表单的输入就在实体主体中. 当然请求的url也可以包含这个数据, 比如在b站搜石原里美, 浏览器的url就成了search.bilibili.com/all?keyword=石原里美.
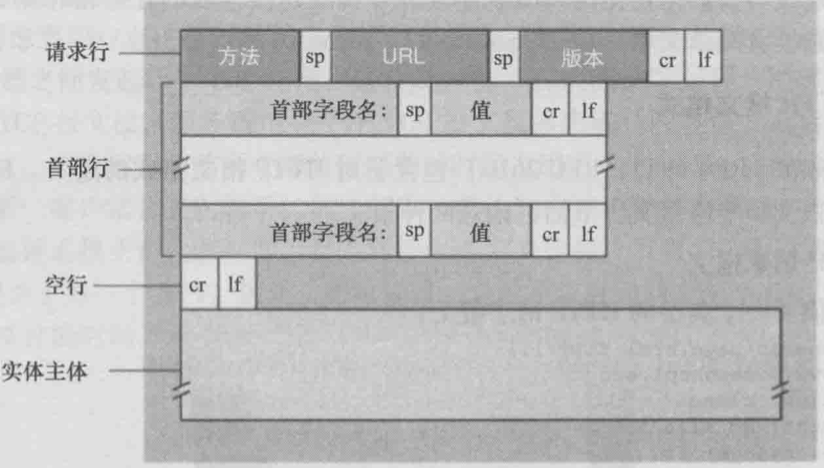
HEAD类似GET, 服务器会使用HTTP报文响应, 但不返回请求对象, 可以用来调试跟踪. PUT一般和Web发行工具一起用, 允许用户上传对象到指定服务器目录, 需要向Web服务器上传对象的app也可以用PUT. DELETE则是删除Web服务器的对象. HEAD类似GET, 但是只获取头.
响应报文
HTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.23 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data...)
响应报文分为一个状态行(status line), 6个首部行(header line), 实体体(entity body). 实体体是报文的主要部分, 包含请求对象本身. 状态行有三个字段: 协议版本, 状态码, 状态信息.
首部行中Connection: close表示非持续连接, 发送报文后关闭连接. Date: Tue, 09 Aug 2011 15:44:04 GMT是服务器在文件系统中检索到对象, 插入到响应报文, 被发送该响应报文的时间. Server: Apache/2.23 (CentOS)表示该报文是Apache Web服务器产生的. Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT表示对象最后的修改时间. Content-Length: 6821表示被发送对象中的字节数. Content-Type: text/html表示实体体中的对象是HTML文本, 注意对象类型应该用Content-Type来指示而不是用文件扩展名.
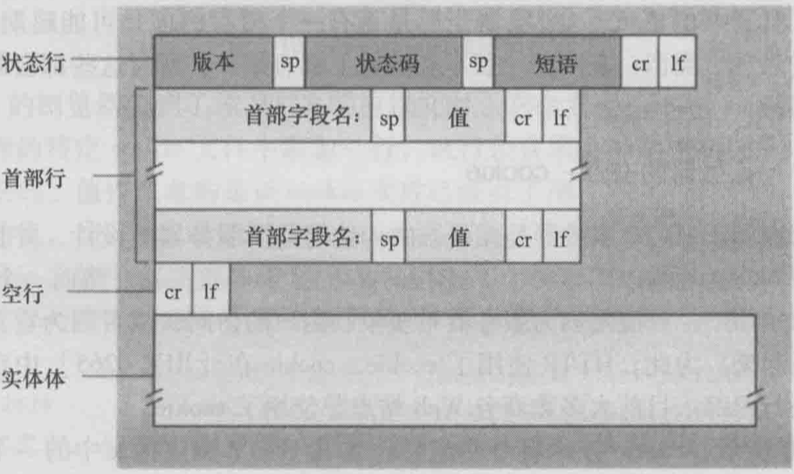
笔试面试经常会问的状态码:
- 200 OK: 请求成功, 信息在返回的响应报文中
- 301 Moved Permanently: 请求的对象被永久转移了, 新的URL定义在响应报文Location: 首部行中, 客户软件自动获取新的URL
- 400 Bad Request: 服务器不理解请求
- 404 Not Found: 被请求的文档不在服务器上
- 505 HTTP Version Not Supported: 服务器不支持请求报文使用的HTTP协议版本.
更一般的:
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | Informational(信息性状态码) | 接受的请求正在处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作一完成请求 |
| 4xx | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
cookie
HTTP服务器本身无状态, 可是为了Web站点去识别用户, 就需要用cookie. cookie技术有四个组件:
- HTTP响应报文中的一个首部行.
- HTTP请求报文中的一个首部行.
- 在用户端系统中保留有一个cookie文件, 由用户浏览器进行管理.
- 位于Web站点的一个后端数据库.
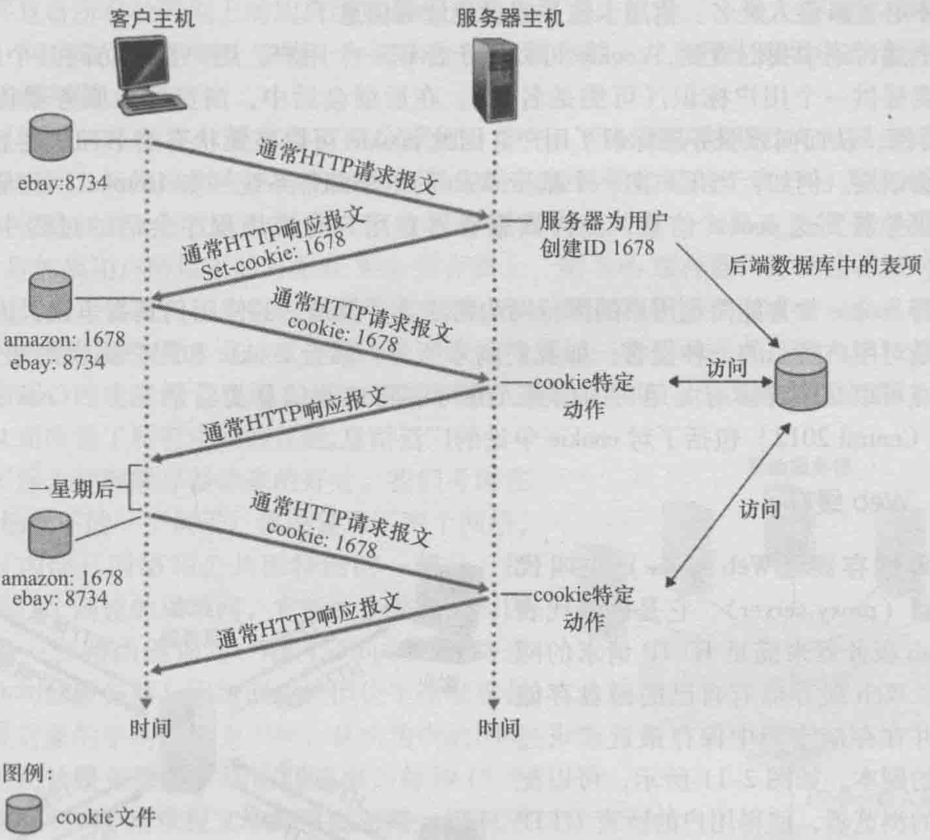
cookie相当于在无状态的HTTP上建立了用户会话层, 如上图, 在客户主机收到了Set-cookie之后, 浏览器就会在其管理的cookie文件中加一行, 包含服务器的主机名和在Set-cookie首部中的识别码. 当客户机继续访问时就会在HTTP请求报文加上这个识别码. Web服务器就由此追踪用户. 比如在淘宝买东西时的购物车就可以通过这种形式来记住某个用户的购物车内容.
Web缓存
Web缓存器(Web cache)也叫代理服务器(proxy server), 能够代表初始的Web服务器满足HTTP请求, Web缓存器有自己的磁盘存储空间, 并在存储空间中存储最近的对象的副本.
- 当浏览器请求时会先与Web缓存器建立TCP链接, 向缓存器发送HTTP请求.
- Web缓存器如果有此对象, 则向浏览器用HTTP响应报文返回该对象. 若无, 则缓存器会和初始服务器建立TCP连接, 发送该对象的HTTP请求, 并获得初始服务器具有该对象的HTTP响应, 缓存器会保存次副本并向客户浏览器发送包含此副本的HTTP响应报文.
所以Web缓存器既是客户又是服务器, 通常由ISP购买并安装. 它大大减少了客户请求的响应时间, 减少一个机构接入链路到因特网的通信量. 下图中, 假设每秒15个请求, 局域网的流量强度就是$15个请求/s * 1Mb/请求 / 100Mbps = 0.15$, 介入链路的流量强度为$15个请求/s * 1Mb/请求 / 100Mbps = 1$. 局域网上0.15的通信量最多导致10ms时延可以忽略, 而链路接近1的流量强度就会让实验非常大, 并且无限增长. naive的方法就是增加接入链路的效率(从15Mbps到100Mbps), 但是代价太高; 所以可以在机构网络中添加一个缓存器, 若命中率是0.4(通常在0.2到0.7), 那么40%的请求会得到缓存器响应, 60%在链路响应, 大大降低了接入链路的流量强度.
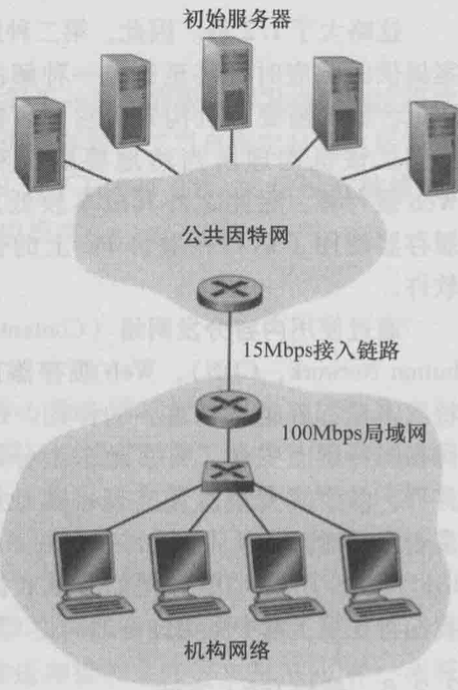
通过**内容分发网络(CDN)**就利用了Web缓存器, CDN公司在因特网分散的地理位置安装缓存器, 去实现流量的本地化.
条件GET方法
高速缓存的问题是缓存器所存储的对象可能已经过时了, 而HTTP可以通过conditional GET来群确认存储的副本是最新的. 如果报文是用的GET方法, 并且请求报文中包含一个IF-Modified-Since首部行, 这个HTTP请求就是conditional GET, 告诉Web服务器如果在这个时间之后如果修改过, 才发送此对象. 如果没有修改, 服务器就会给缓存器一个304 Not Modified, 缓存器就可以给浏览器发送已经保存的副本. 如果修改了, 则服务器会返回普通的200 OK.
FTP
todo
SMTP
todo
DNS
域名系统(Domain Name System)也是面试的常考点. 对于因特网的主机来说, 识别方法是他的hostname, 比如bilibili.com, 这是方便人记忆的, 但是在网络中, 主机是由IP地址来标识的, 所以需要通过DNS来把主机名转换为IP地址.
DNS服务
DNS服务包含一种转换hostname到IP地址的服务. DNS是由分层的DNS服务器实现的分布式数据库, 使主机能够查询分布式数据库的应用层协议. 运行在UDP之上, 使用53号端口. HTTP/SMTP/FTP这些应用层协议都可以使用DNS服务.
若一个浏览器请求URL www.someschool.edu/index.html,为了是用户主机的HTTP请求报文发送到www.someschool.edu这个Web服务器, 就必须得知道这个服务器的IP地址, 做法如下:
- 同一台主机上运行DNS应用的客户端
- 浏览器从URL中抽取主机名www.someschool.edu, 并将其传给DNS客户端
- DNS客户向DNS服务器发送一个包含主机名的请求
- DNS客户收到回答报文, 其中含有该主机名的IP地址
- 浏览器向该IP地址80端口的HTTP服务器发起TCP连接.
除此之外, DNS还提供以下服务:
- 主机别名(host aliasing): 主机有多个名字, 包括规范主机名(canonical hostname)和主机别名, 应用程序可以通过DNS来获得主机别名对应的规范主机名和主机IP地址.
- 邮件服务器别名(mial server aliasing): 电子邮件的别名, 主要还是方便记忆.
- 负载分配(load distribution): DNS也用于在冗余的服务器之间进行负载分配, 繁忙的站点由多台服务器支撑, 这些服务器的IP地址集合和同一个规范主机名相联系. 当客户对这个地址集合发出DNS请求时, 服务器会响应整个IP集合, 但是每次响应都会旋转这个IP地址的顺序. 虽然客户总是向到地址集的第一个发送HTTP请求报文, 但是DNS就可以在这些冗余的Web服务器之间循环分配负载.
DNS工作原理
DNS最简单的设计就是在因特网上只用一个DNS服务器, 其包含所有的映射. 但是这样就有单点故障(DNS服务器崩了, 整个因特网就崩了), 通信容量(单个服务器处理过多的请求), 远距离集中式数据库(距离过远, 延迟严重), 维护(困难)的问题. 所以DNS采用了分布式的方案.
DNS服务器大致分分类:
- 根服务器: 因特网有13个根服务器, 每个服务器都是冗余的服务器网络
- 顶级域服务器: 负责顶级域名(com/org/net/edu/gov, cn/uk/fr)
- 权威服务器: 通常是组织自己拥有的吗比如学校, 公司一般就会有自己实现以及维护的权威DNS服务器
- 本地服务器: 通常临近主机, 居民区中本地服务器和主机可能就相隔几台路由器.
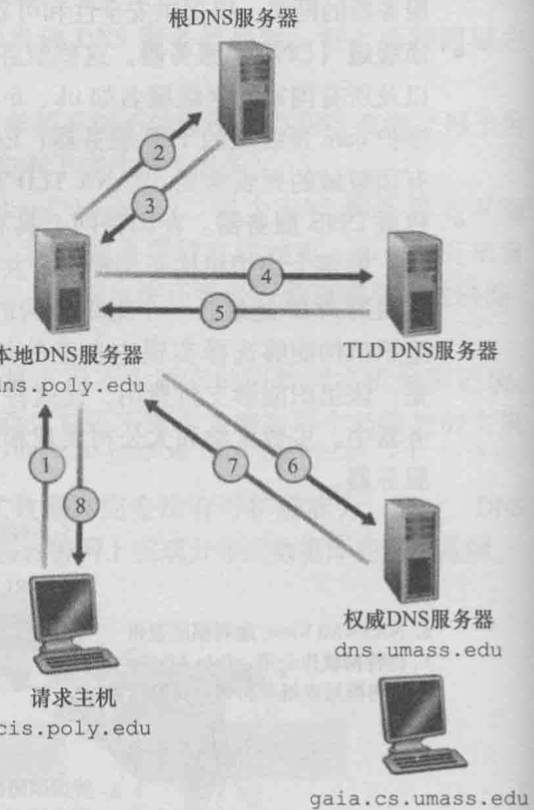
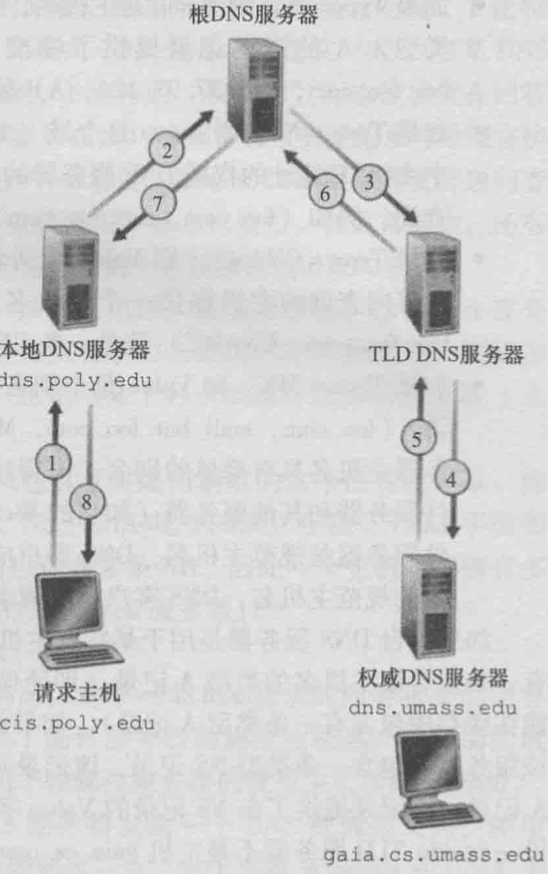
下图中一共发送了4份查询报文和4份回答报文. 从cis.ploy.edu到dns.ploy.edu是递归查询, 后面的三个查询都是迭代查询. 实际上TLD可能不知道权威服务器的IP, 所以还需要通过中间的DNS服务器, 来获得前卫服务器IP地址.
下图是纯递归的.
DNS缓存表示在某DNS服务器接受回答之后, 能缓存到该服务器中, 也就是把主机名和其所对应的IP共同记录, 因为这种映射不是永久的, 所以一段时间后DNS服务器可能会丢弃缓存信息. 主机域名解析顺序:
- 浏览器缓存
- 找本机hosts文件
- 路由缓存
- 找DNS服务器(本地, 顶级, 根)
DNS记录和报文
共同实现DNS分布式数据库的所有DNS服务器存储了资源记录(Resource Record, RR), 其提供主机名到IP地址的映射.
每个DNS回答包含了一条或多条RR. RR包括了Name, Value, Type, TTL这样一个四元组. TTL记录生存时间(下面例子中忽略). Name和Value取决于Type.
- Type=A, 则Name为主机名, Value对应其IP地址, 把域名解析到IP地址. eg. (relay1.bar.foo.com, 145.37.93.126, A)
- Type=NS, 则Name为个域(foo.com), Value为知道如何获得该域中主机IP的权威DNS服务器的主机名. eg. (foo.com, dns.foo.com, NS)
- Type=CNAME, Value是别名为Name的主机对应的规范主机名, 简单的说就是把域名解析到另外一个域名. 如果使用CDN服务, 供应商就可以给你一个地址, 而ip地址可以灵活地变化, 实现CDN加速. eg. (foo.com, relay1.bar.foo.com, CNAME)
- Type=MX, 则Value是别名为Name的邮件服务器规范主机名. eg. (foo.com, relay1.bar.foo.com, MX)
DNS报文
格式如下.
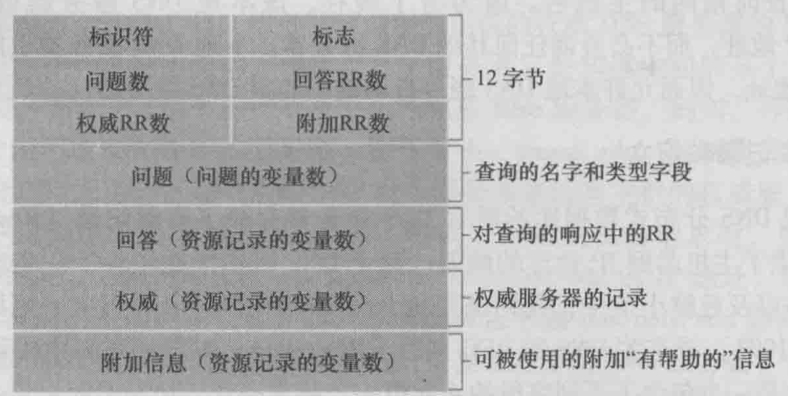
- 前12字节是首部区域. 标识符是16bit数, 用于标识该查询. 标志字段有若干编制, 比如1bit的"查询(0)/回答(1)“指出报文的类型.
- 问题包括正在进行的查询该信息(被查询的主机名, 询问问题类型如A/MX)
- 回答包括Type, Value, TTL字段, 可能有多个, 因为主机可能有多个IP地址
- 权威包含其他权威服务器的记录
说DNS是运行在端口号53的UDP协议之上实际上是不严谨的, 虽然大多数域名厂商只支持UDP的域名解析, 但是根据RFC1035的4.2, 有这么一句话: The Internet supports name server access using TCP [RFC-793] on server port 53 (decimal) as well as datagram access using UDP [RFC-768] on UDP port 53 (decimal). 并且提到了UDP最大支持512个byte, 其实DNS解析查询优先使用 UDP, 当UDP完成不了的情况下, 而且支持解析支持TCP的话, 就转换TCP查询.
P2P应用
我的实现: circular-DHT.
实验
HTTP
当http请求1次以上, 就有了If-Modified-Since: Tue, 20 Oct 2020 05:59:01 GMT. 响应是304, 也没有了第一次响应时的Line-based text data: text/html (4 lines).
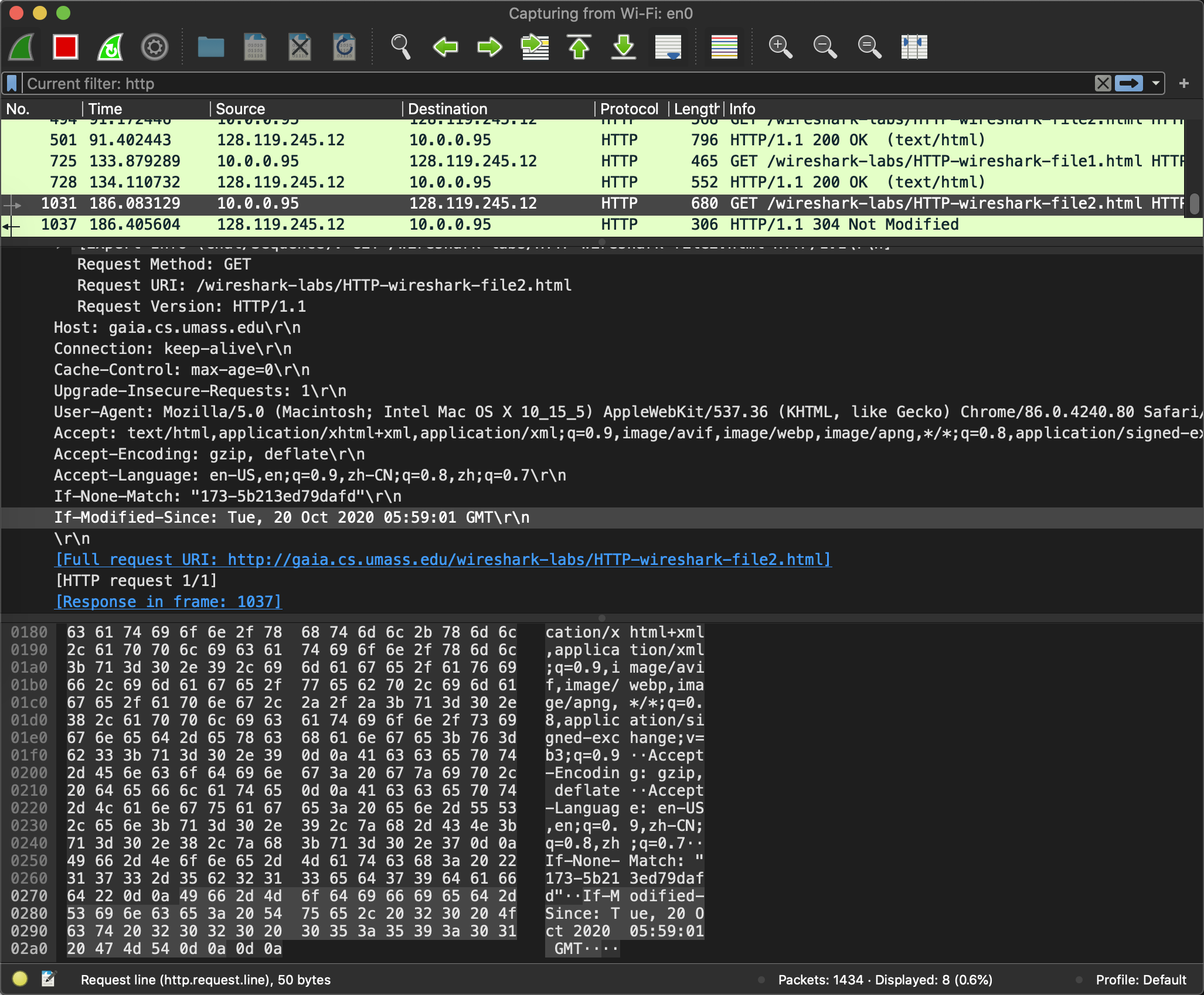
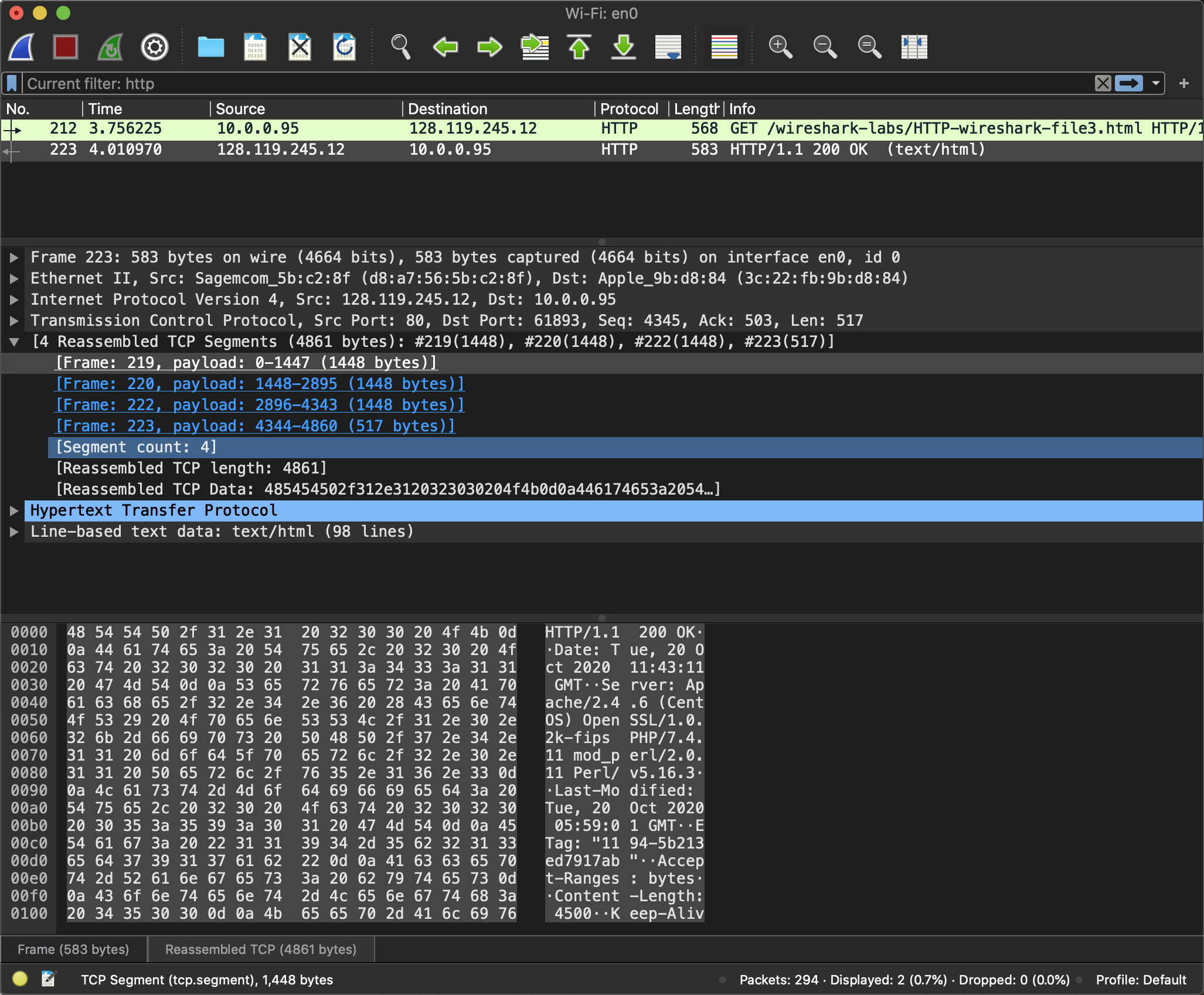
向http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file3.html发起HTTP请求, 因为html文件比较大, 就被拆分成了4个TCP的报文段.
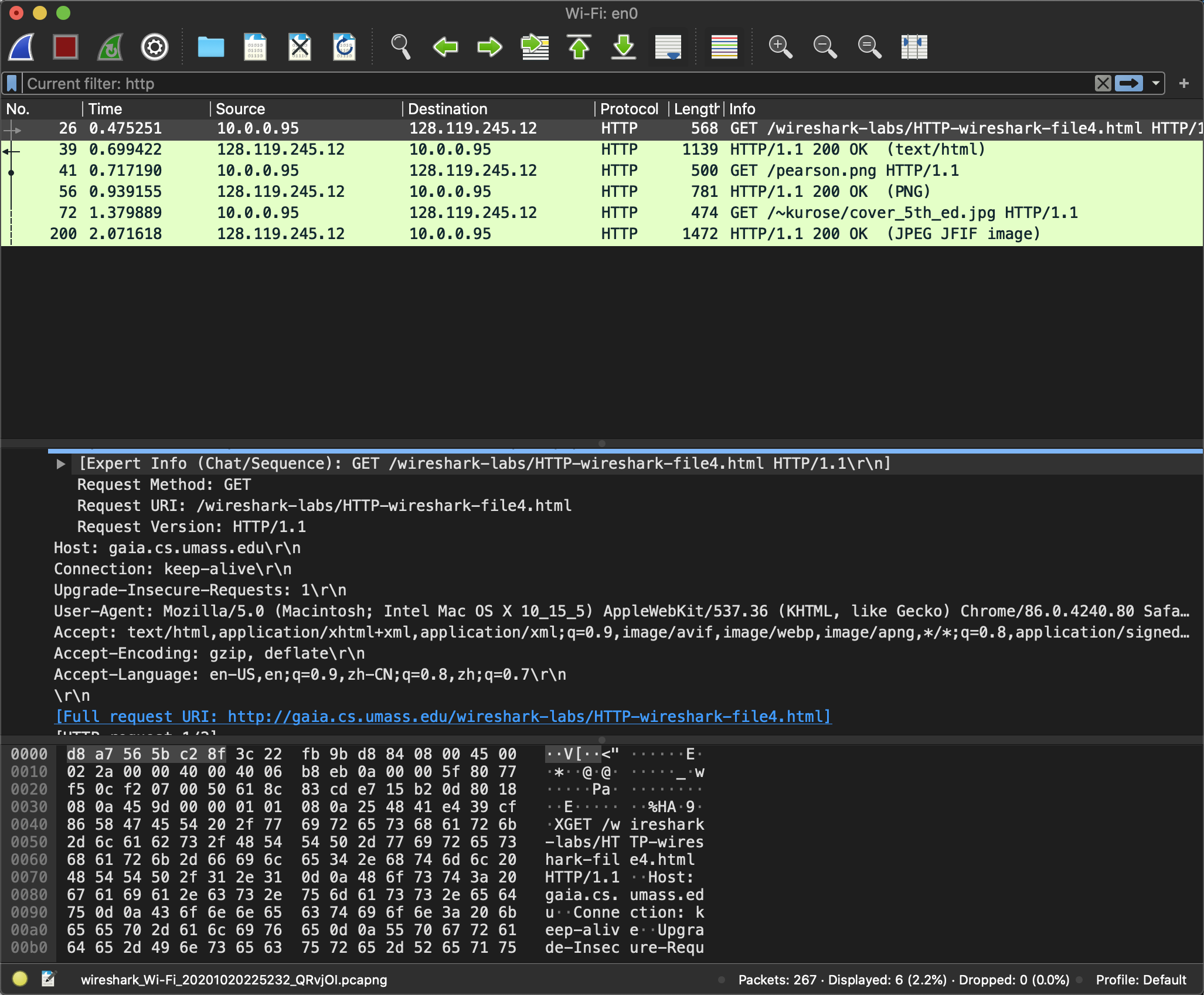
向http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html发起HTTP请求, 这是多个对象的html, 发现发生了三次GET. 而且因为Connection: Keep-Alive, 可以知道是串行下载的两张图片而不是并行.
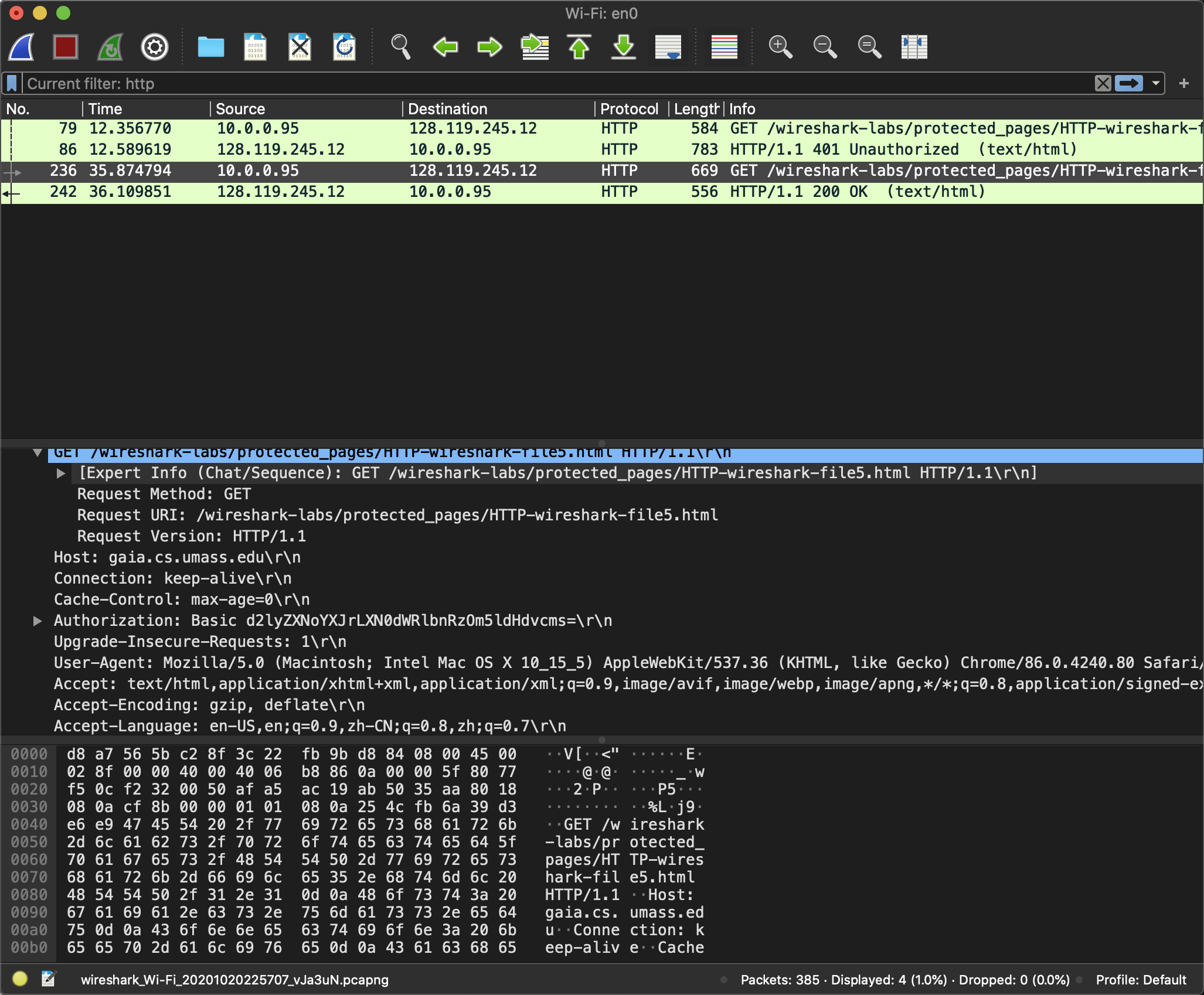
向http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html发起HTTP请求, 这是需要认证的HTTP, 在输入用户名和密码之后才能访问. 在第二次的GET中出现了Authorization: Basic d2lyZXNoYXJrLXN0dWRlbnRzOm5ldHdvcms=\r\n, 并得到200响应.
DNS
DNS实验有些部分已经没法复现了. 我以这个实验为参考过一遍各个知识点. nslookup可以根据主机名找到其对应的DNS服务器. 输入nslookup www.baidu.com. 前两行是给出答案的DNS server的名字和地址. 后面就是答案. 其实dig更好用, 还是建议用dig. nslookup用来交互式查询更好.
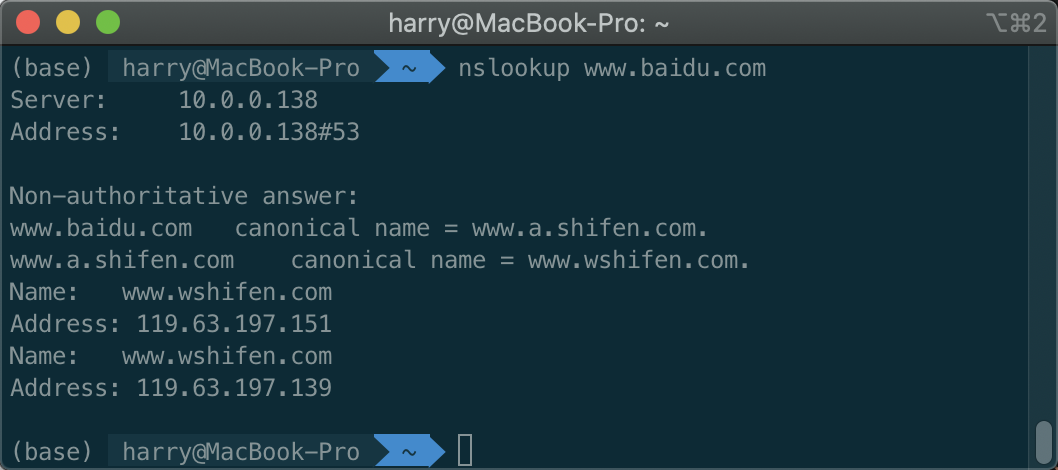
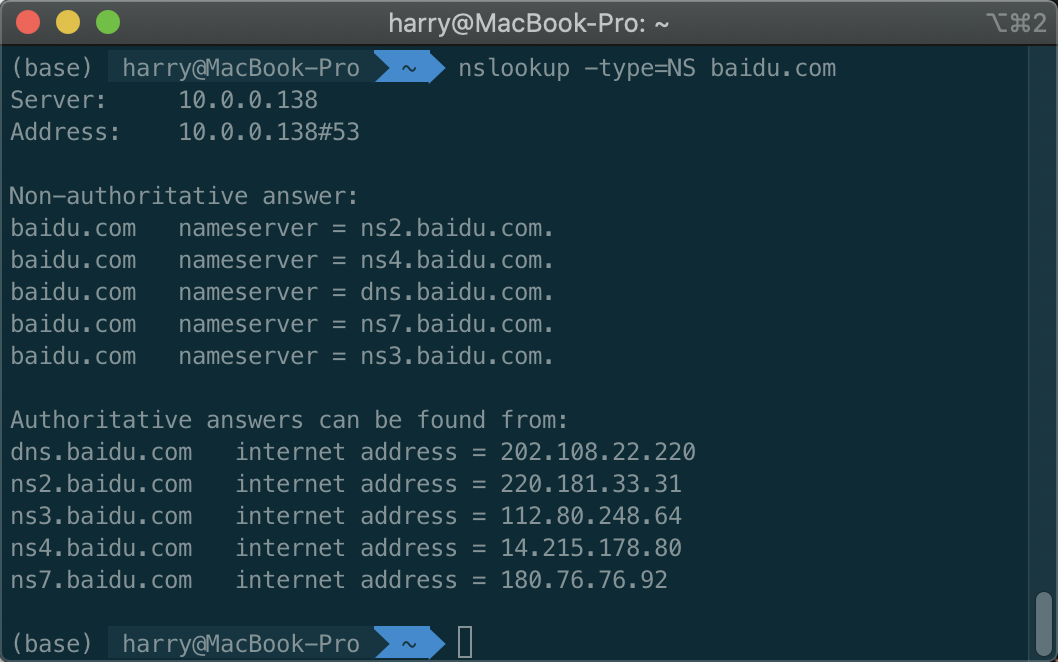
输入nslookup -type=NS baidu.com, 如果不用type, 就是默认的type A. non-authoritative顾名思义, 就是非权威服务器返回的结果, 可能来源于缓存. 如果-type=MX, 就可以查询邮件服务器了.
提一个小知识点,
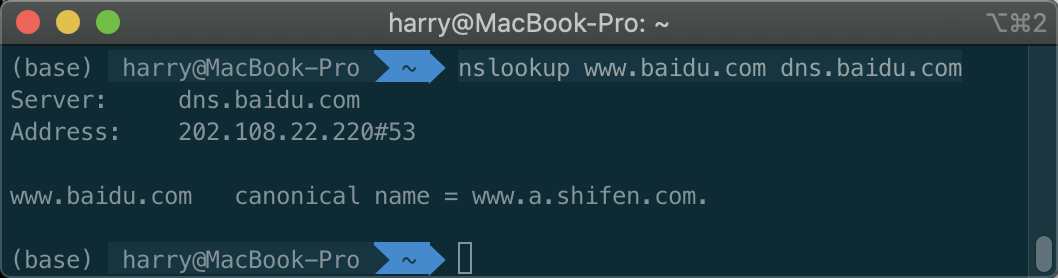
www.baidu.com和baidu.com指向的是不同的ip, 用dig试试. 一个经历多个cname最后a到了ip, 一个直接a到ip.
那么我们尝试直接去访问权威DNS服务器, nslookup www.baidu.com dns.baidu.com, 得到下图. 这个时候非权威的答案就不会出现了. dns.baidu.com代表强制访问这个DNS服务器而不是默认的那个.
接下来试一下ipconfig/ifconfig. mac用后者.
接着用wireshark来分析下DNS. 首先清除缓存sudo killall -HUP mDNSResponder, 浏览器也要清除下缓存. 浏览器输入https://www.ietf.org, 这里可以看到发送端口并不是53, 查协议发现DNS应该只是限制了server的端口. 同时也应证了DNS通过UDP通信(大多数). 最后得到了4个answer.
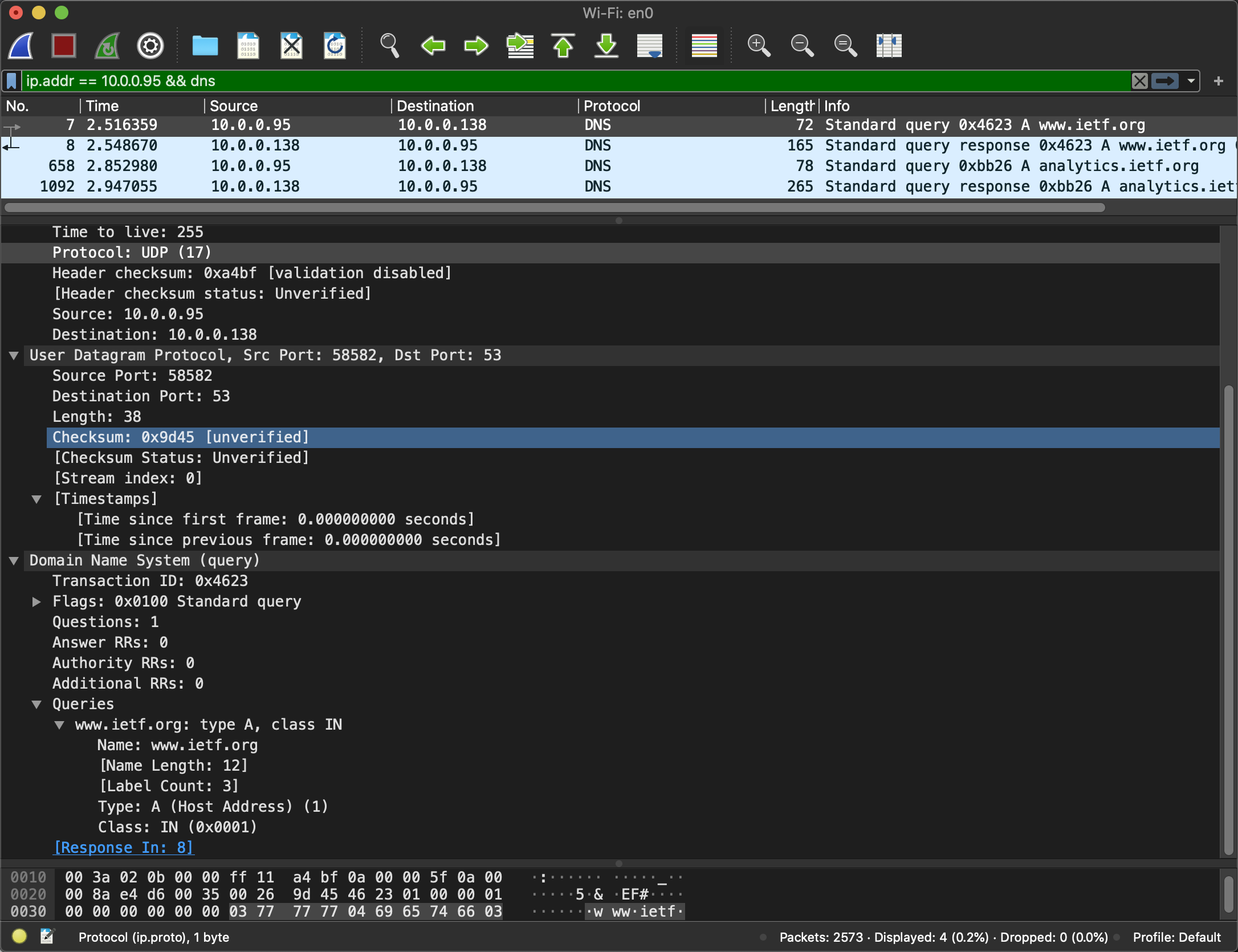
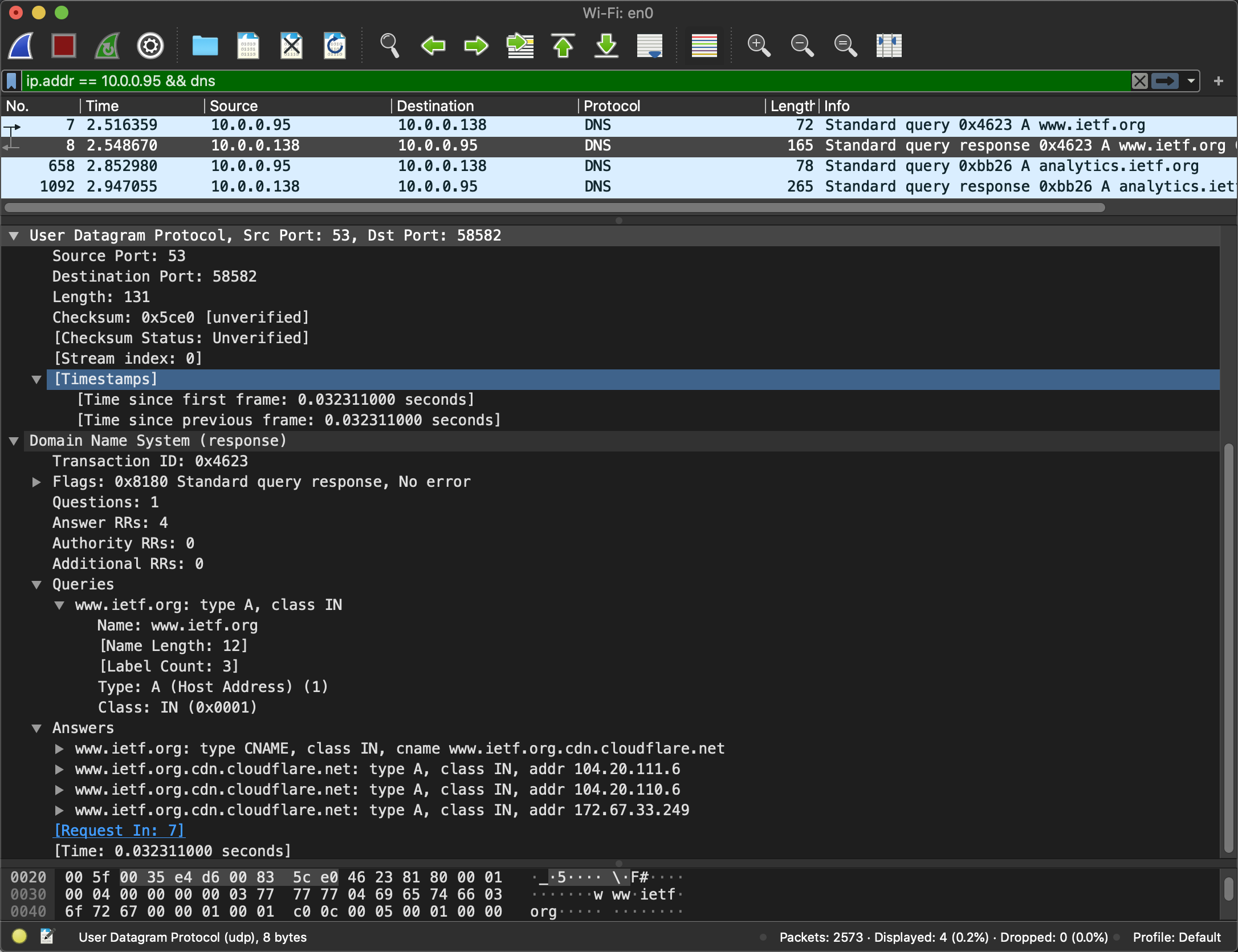
参考
- 计算机网络-自顶向下方法(第6版)
- Computer Networking A Top-Down Approach(7th edition)
- 作业
- 习题答案
- wireshark实验
- 状态码表格
- 计算机网络总结-codesheep
- 什么情况下DNS会使用TCP传输协议?
- cname记录是什么
- DNS原理入门
comments powered by Disqus